아호코라식 알고리즘은 문자열을 검색하는 알고리즘이다. 검색할 단어가 10개 일 때 검색 대상 문자열도 일일이 10번 탐색하는 게 아니라 찾을 검색어가 아무리 많아도 한 번만 탐색하여 결과를 얻을 수 있다. 시간복잡도가 O(n + m + z) 로 제곱이나 log 가 붙는게 아닌 선형적으로 증가하므로 속도가 빠른 검색 알고리즘에 속한다.
n: 텍스트의 길이m: 모든 패턴의 총 길이z: 텍스트 내에서 발견된 패턴의 총 출현 횟수
※ 용어 정리 - 텍스트, 패턴
필자는 논문이나 구글링을 할 때 많이 출현하는 용어 텍스트와 패턴의 의미가 헷갈렸었다.
💡 텍스트 → 검색 대상 문자열 or 단어들
패턴 → 검색어
로 이해하면 쉽다. 예를 들면 텍스트와 패턴이 아래와 같을 때,
💡 텍스트: [사과, 오렌지, 사과주스, 수박]
패턴: 사과
n, m, z 의 값은
n(텍스트의 길이): 11 (= 2+3+4+2)m(모든 패턴의 총 길이): 2z(텍스트 내에서 발견된 패턴의 총 출현 횟수): 2 (사과, 사과주스)
가 된다.
아호코라식 알고리즘 이해하기

INPUT
- 검색어: ushers
- 검색 대상 단어: [he, she, his, hers]
OUTPUT
- 검색 결과 단어: [she, he, hers]
아호코라식 알고리즘은 검색어와 매칭되는 문자열 혹은 단어들을 반환해주는 일을 한다. 알고리즘은 패턴의 state 에 따라 검색 결과를 반환해주는 Pattern matching machine 으로 구성되어 있다고 논문에서 설명하고 있다.
A pattern matching machine for K is a program which takes as input the text string x and produces as output the locations in x at which keywords of K appear as substrings.
그럼 state 가 뭔지, Pattern matching machine 은 탐색 방법은 무엇인지, 데이터는 어떻게 구성하는지 알아보자!
검색 결과에 나올 단어들은 어떻게 판별할까?
Pattern matching machine 은 검색어와의 매칭 여부 판단을 위해 goto(), failure(), output() 세 가지 함수로 구성되어 있다.
① goto()
검색 대상 단어들을 문자 단위로 쪼개 Trie 라는 자료구조로 저장해놓는다.
검색어를 goto() 를 통해 한 문자씩 이동하면서 매칭된 문자가 있는지 판단한다.
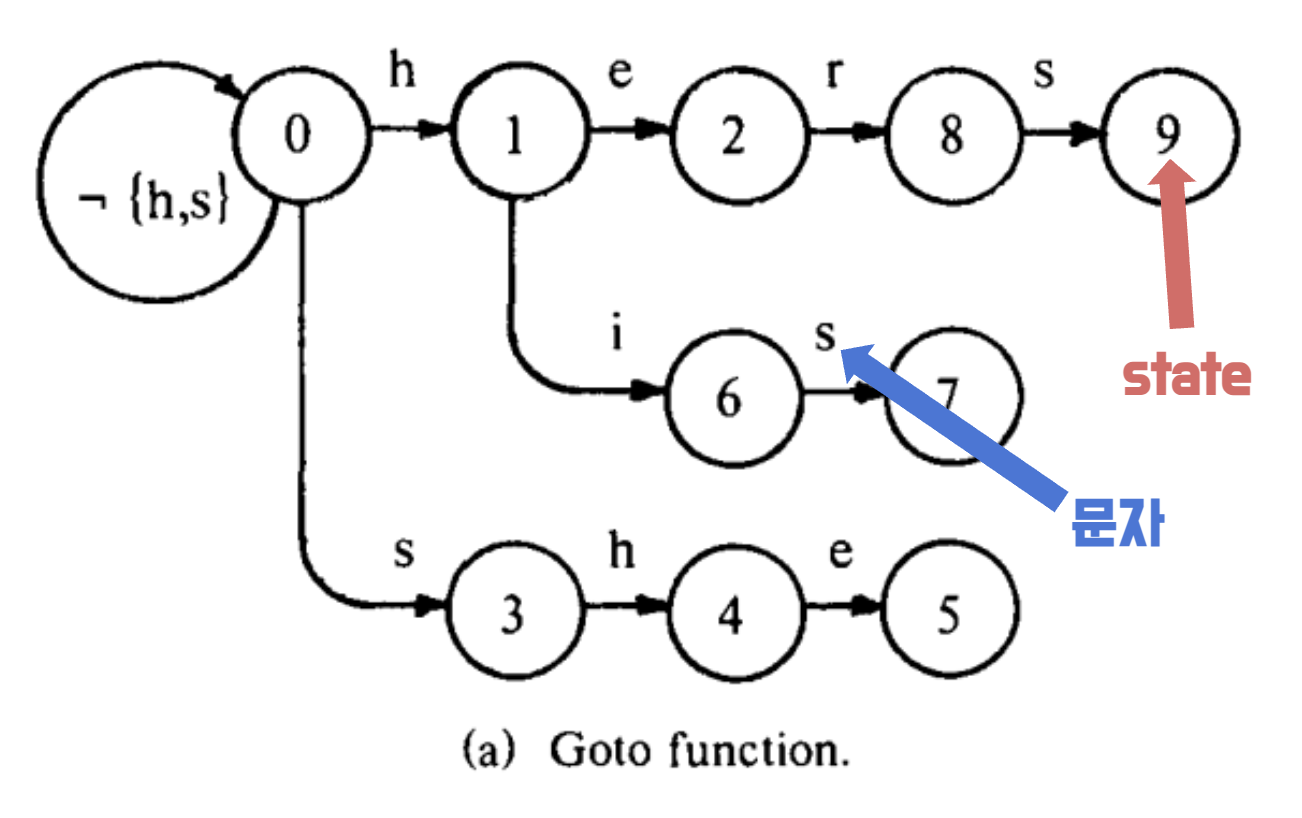
여기서 동그라미안의 숫자를 state 라고 한다. 검색 대상 단어들을 쪼갠 문자의 각 위치(position)값이다. state 의 역할은 문자 하나 하나에 대한 ID 이다. 아래에 나올 failure() 이나 output() 도 state 를 key 값으로 활용한다.
💡 Trie 자료구조란
트리 형태이며 한 문자씩 쪼개 노드 하나에 문자 하나를 저장한다.
문자 탐색을 효율적으로 할 수 있는 자료구조이다. ([위키])
② failure()
goto() 로 문자를 이동하다가 매칭에 실패했을 때 어디 state 로 이동해야할지 알려준다.
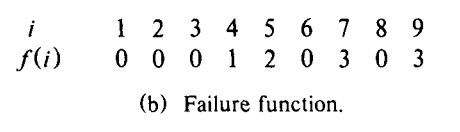
③ output()
state 에 도달했을 때 검색 대상 단어들을 반환한다.

자, 그럼 goto(), failure(), output() 세 가지 함수를 활용해 검색 흐름을 직접 따라가보자!
검색 과정
검색어는 ushers 이다. Trie 로 저장된 단어들 [he, she, his, hers] 중에서 u, s, h, e, r, s 순으로 찾아보도록 한다.
(1) u (u → s → h → e → r → s)
g(0, u) = fail
state 0 에서 시작한다. 단어들 중에 u 로 시작하는 단어가 없다. 다음 문자 s 로 넘어가자.

(2) s (u→ s → h → e → r → s)
g(0, s) = 3
오 s 가 존재하므로 state 3 번으로 이동하자!
💡 g(0, s) = 3 의 의미
g: goto 함수
state 0 에서 문자 s 를 거치면 state 3 에 도달한다는 의미
그림을 수식으로 표현한 것이다.
state 를 이동했으니 검색 결과로 나와줄 output 이 있는지 확인해보자
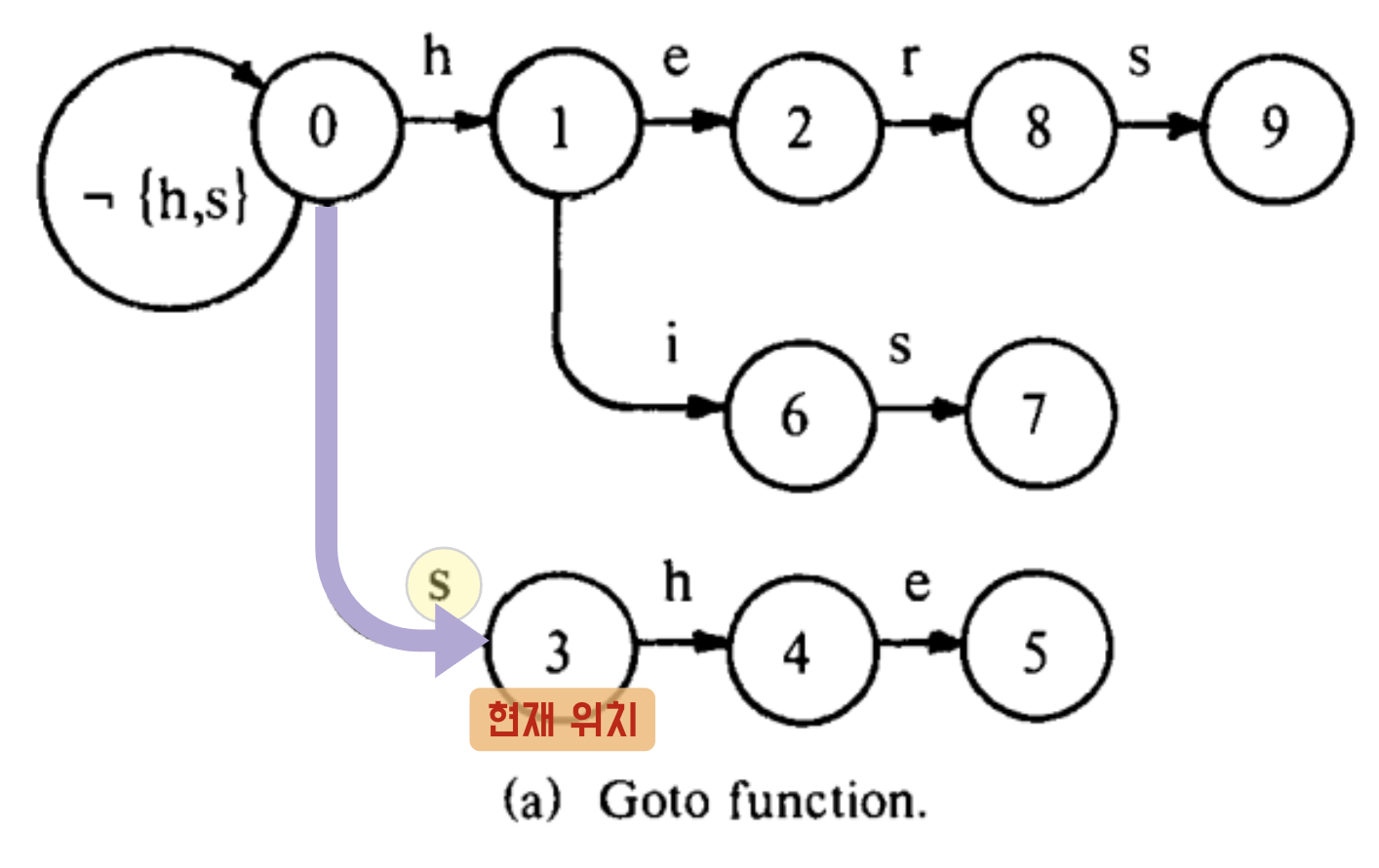
output(3) = empty
아직 검색 결과는 없다. 다음 문자 h 로 넘어가자.

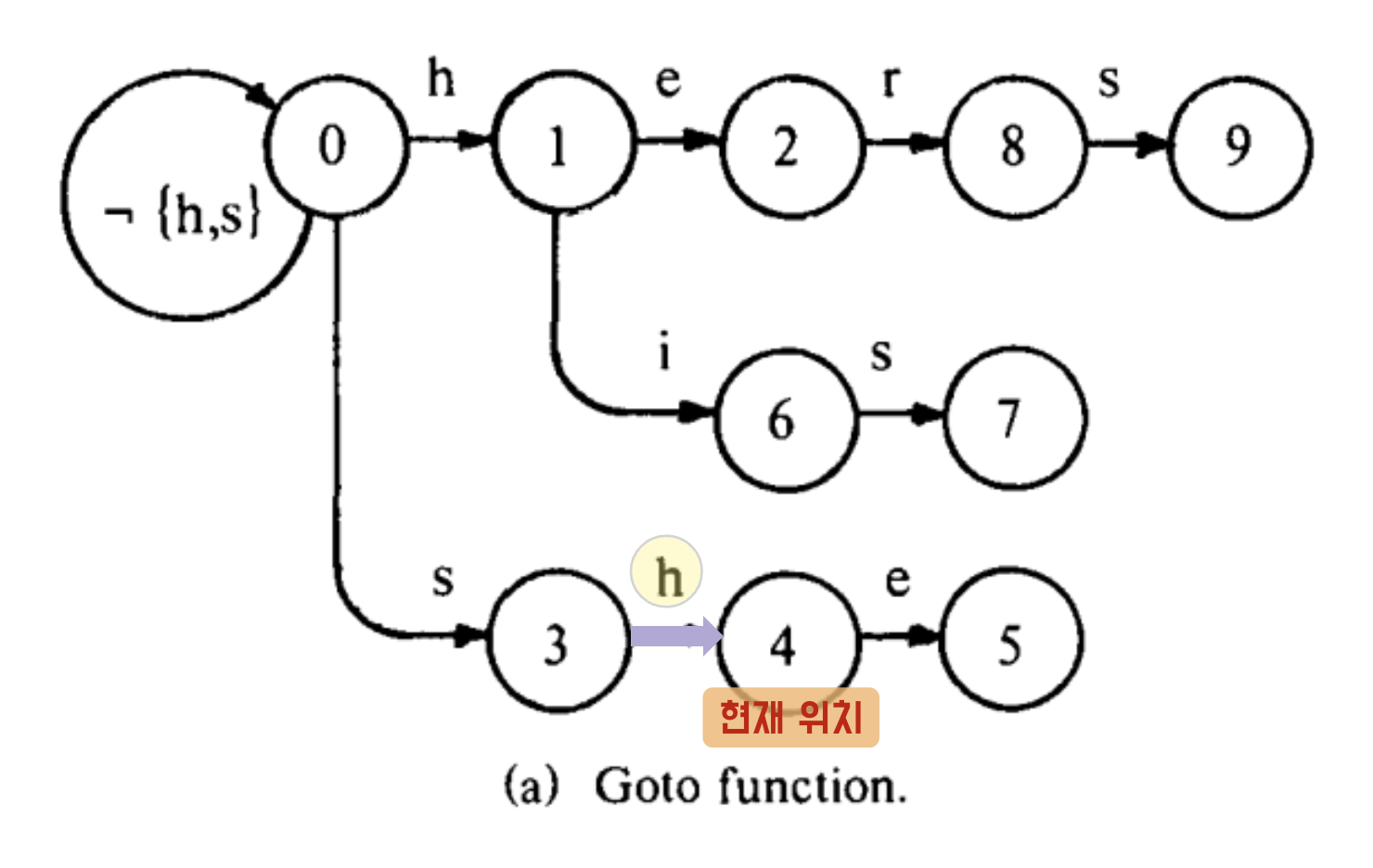
(3) h (u→ s → h → e → r → s)
g(3, h) = 4
현재 state 3 에서 h 를 거쳐 state 4 로 이동 가능하다!
output(4) = empty
아직 검색 결과 단어는 없다.
(4) e (u→ s → h → e → r → s)
g(4, e) = 5
현재 state 4 에서 e 를 거쳐 state 5 로 이동한다.

output(5)= {she, he}
드디어 검색 결과 존재! 2개나 존재한다. 검색 과정이 끝날 때까지 잘 보관해 놓는다.

(5) r (u→ s → h → e → r → s)
g(5, r) = fail
state 5 에서 r 을 거칠 수 없어 fail 이 발생했다.
f(5) = 2
그래서 fail 함수를 확인해보니 state 5 에서 fail 이면 state 2 로 이동하라고 한다.

g(2, r) = 8
fail() 을 통해 이동한 state 2 에서 r 를 거쳐 state 8 로 이동한다.

output(8) = empty
state 8 에 매핑되는 검색 결과 단어는 없다.
(6) s (u→ s → h → e → r → s)
g(8, s) = 9
state 8 에서 s 를 거쳐 state 9 로 이동한다.

output(9)= {hers}
검색 결과 hers 가 존재한다.
모든 문자를 돌았으므로 검색 과정을 종료한다.

최종적으로 검색어 ushers 에 대한 검색 결과는 {she, he, hers} 가 된다.
검색 과정에서는 세 함수에 이미 input 과 output 이 정의되어 있었다. 그럼 이 데이터 자체는 어떻게 만드는지 궁금하지 않은가?
데이터 구축에 관해서는 글이 너무 길어져 다음 편에 작성하겠다!
다음글: https://elsboo.tistory.com/84
[아호코라식 (Aho-corasick) 알고리즘] 논문 이해하기 (2) - 데이터 구축
이전 글에서는 아호코라식 알고리즘의 검색 과정에 대해서 알아보았다. 이번 글에서는 아호코라식이 구성하는 세 개 함수 goto(), output() , failure() 의 데이터를 구축하는 법에 대해 알아보자 함수
elsboo.tistory.com
레퍼런스
http://cr.yp.to/bib/1975/aho.pdf
글 읽어주셔서 언제나 감사합니다. 좋은 피드백, 개선 피드백 너무나도 환영합니다.
'SearchDeveloper > 알고리즘' 카테고리의 다른 글
| 코사인 유사도 증명하기 (1) | 2024.12.07 |
|---|---|
| [아호코라식 (Aho-corasick) 알고리즘] 논문 이해하기 (3) - 성능 측정 (2) | 2024.07.24 |
| [아호코라식 (Aho-corasick) 알고리즘] 논문 이해하기 (2) - 데이터 구축 (0) | 2024.04.14 |
| 편집 거리 알고리즘 이해하기 (0) | 2022.12.11 |
| ElasticSearch BM25 이해하기 (5) | 2022.08.25 |


