다음 3개의 문서가 있다.
[문서 1] 눈을 떠보니 커피 없는 세상에 와버렸다.
[문서 2] 너도 커피 좋아해? 나도 커피 좋아해
[문서 3] 저기 저 앞에 커피 파는 가게가 있다. 한 번 가볼래? 그래 내가 쏠게 마시러 가보자사용자가 “커피” 를 검색한다. 당신은 검색엔진이고 “커피” 와 가장 관련있는 순으로 검색 결과를 내보내야한다면 문서 순위를 어떻게 지정할 것인가?
만약 2, 1, 3 순이라고 답했다면 축하한다! 당신은 BM25를 이해했다.

날짜, 불리언 같은 간단한 필드를 검색할 때는 답이 정확이 존재하기 때문에 정답 문서를 찾는 것이 명확하다. 하지만 책, 뉴스 기사, 공고 내용 같은 full-text 로 구성된 필드를 검색하는 것은 비교적 명확하지 않다. 왜냐하면 full-text 검색은 문서가 정답이냐 아니냐를 따지기 보다, 검색어와 문서가 얼마나 관련 있는지를 판단하고 관련도가 높은 문서 순으로 정렬을 해주는 방식이기 때문이다. 이 때 그 “관련도”를 계산해주는 것이 바로 BM25 알고리즘이 하는 일이다.
BM25는 다음 조건을 만족할수록 더 큰 점수를 부여한다.
- 문서 내용에 검색어 출현 빈도가 높을수록
- 다른 문서에는 검색어가 출현하지 않을수록
- 문서 내용이 짧을수록
BM25는 ElasticSearch 5.0, Lucene 6.0 부터 디폴트 스코어링 알고리즘으로 채택되었다. 이전 디폴트였던 TFIDF 와 판단 방식은 비슷하지만 다음과 같은 차이가 있다.
[Term Frequency 관점]
- TFIDF: 한 문서에 검색어가 많이 출현 할수록 점수는 높아
- BM25: 한 문서에 검색어가 많이 출현 할수록 좋지만 한계치를 넘어가면 점수는 거기서 거기야
[Document Frequency 관점]
- TFIDF: 검색어가 출현한 문서 수가 많을 수록 점수는 낮지만 한계치를 넘어가면 점수는 거기서 거기야
- BM25: 검색어가 출현한 문서 수가 많을 수록 더 낮은 점수를 줄 거야. 한계치를 넘어가면 점수는 급격하게 떨어져
그럼 이제 BM25의 개념들을 수식으로 표현해보자
이제부터는 [검색어] 를 [텀(term)] 으로 부르겠다.

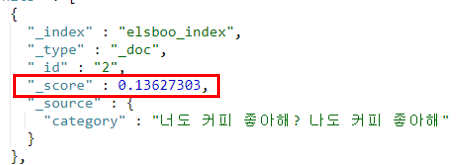
- {문서 d} = 너도 커피 좋아해? 나도 커피 좋아해
- {q} = [너도, 커피, 좋아해?, 나도, 커피, 좋아해]
- {텀 t} = q 에 있는 텀 하나
ⓞ {문서 d} 의 최종 점수 = 각 {텀 t}에 대한 점수의 총 합

{문서 d} 의 BM25 점수는 {텀 t} 하나 하나에 대한 점수를 구한 후 모두 더한 값이다.
① 문서 내용에 검색어 출현 빈도가 높을수록

◈ f(t,d) : {문서 d} 에서 {텀 t} 가 출현한 횟수
- {문서 d} 에서 “커피” 가 2번 출현했으므로
f(t,d)는 2 이다.
◈ K1 : saturation parameter
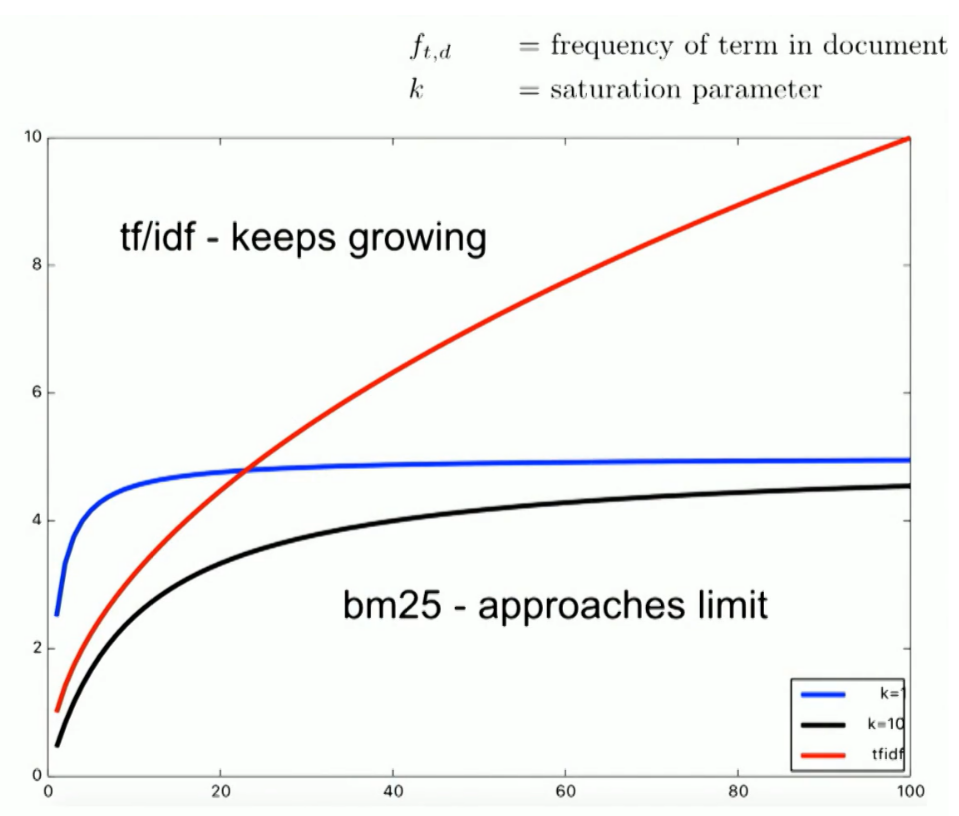
- 기존 TFIDF 와 다르게 BM25는 텀 출현 수(f)가 한계치에 도달하면 더 이상 출현 수로 인한 점수 부여는 하지 않는다. 즉 100억 번 출현하나 1000억번 출현하나 출현 수로 인한 점수 차이는 없다는 뜻이다. 포화 상태이면 더 이상 증가하지 않는다는 뜻에서 이런 곡선을 포화 곡선(saturation curve) 이라고 하며
k1는 saturation curve 을 구현하기 위한 saturation parameter 이다. - ElasticSearch 에서는 디폴트
k1값은 1.2 이다.
② 문서 내용이 짧을수록

◈ fieldLen : {문서 d} 의 길이
fieldLen = 20
너도 커피 좋아해? 나도 커피 좋아해 ⇒ 20 자
◈ avgFieldLen : 모든 문서의 평균 길이
avgFieldLen = 29.67 = (22 + 20 + 47) / 3
[문서 1] 눈을 떠보니 커피 없는 세상에 와버렸다. ⇒ 22 자
[문서 2] 너도 커피 좋아해? 나도 커피 좋아해 ⇒ 20 자
[문서 3] 저기 저 앞에 커피 파는 가게가 있다. 한 번 가볼래? 그래 내가 쏠게 마시러 가보자 ⇒ 47 자
◈ b : 문서 길이를 점수에 반영하는 정도를 조절하기 위한 상수
b가 0이면 문서 길이가 BM25 점수에 반영되지 않으며, b가 클수록 점수에 더 크게 반영된다.
③ 다른 문서에는 검색어가 출현하지 않을수록
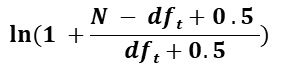
◈ N : 총 문서 수
총 문서는 3건 이므로 N 은 3이다.
◈ df : {텀 t} 가 출현한 문서 수
[문서 1], [문서 2], [문서 3] 에서 모두 “커피” 가 출현하므로 df 는 3이다.
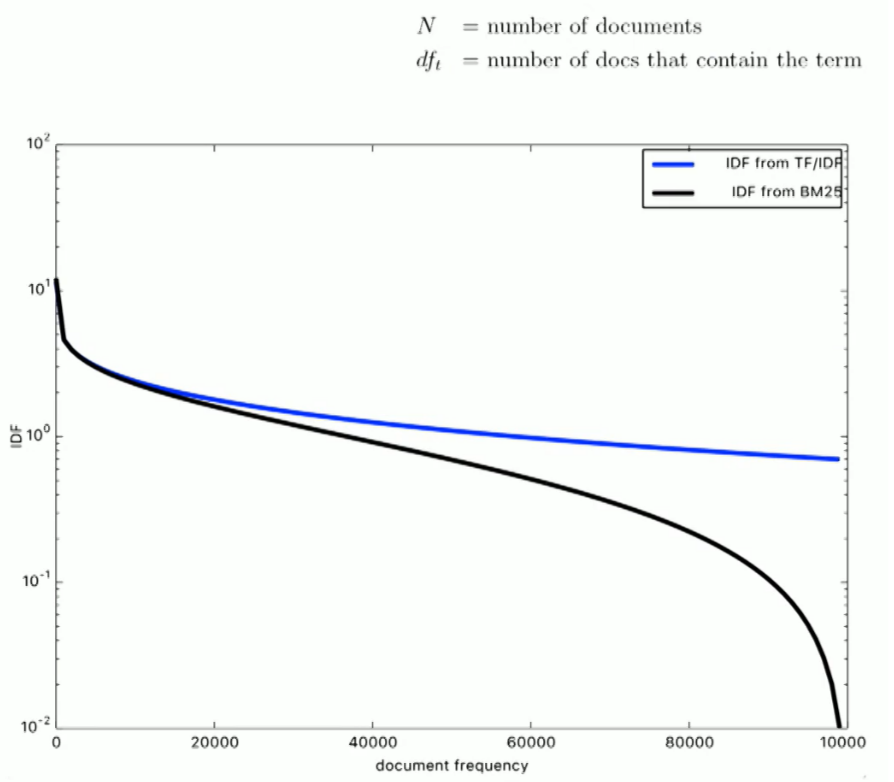
다른 문서에도 많이 출현할수록 점수가 낮아진다는 개념은 기존 TFIDF 에서도 사용하던 개념이다. 그 차이점은 차트에서 볼 수 있듯이 BM25는 출현 문서가 많아지면 많아질수록 기존 TFIDF 보다 패널티를 더 많이 준다.
※ 같은 검색어일 때 IDF 는 문서마다 모두 같은 값을 갖는다. (총 문서 수와 텀이 출현한 문서 수는 모두 같으므로)
다시 정리해보면
BM25 알고리즘은
- 문서 내용에 검색어 출현 빈도가 높을수록
- 다른 문서에는 검색어가 출현하지 않을수록
- 문서 내용이 적을수록
더 큰 점수를 부여한다.
위 개념을 구현한 수식은 아래와 같고,
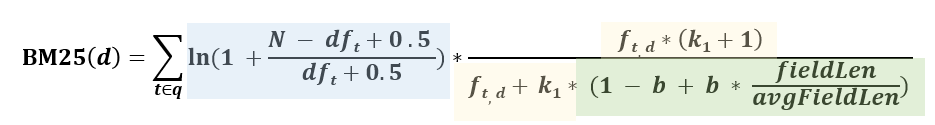
ElasticSearch에서는 _score 필드에 점수를 저장한다.
ElasticSearch BM25 이해하기
글 읽어주셔서 언제나 감사합니다. 좋은 피드백, 개선 피드백 너무나도 환영합니다.
레퍼런스
'SearchDeveloper > 알고리즘' 카테고리의 다른 글
| 코사인 유사도 증명하기 (1) | 2024.12.07 |
|---|---|
| [아호코라식 (Aho-corasick) 알고리즘] 논문 이해하기 (3) - 성능 측정 (2) | 2024.07.24 |
| [아호코라식 (Aho-corasick) 알고리즘] 논문 이해하기 (2) - 데이터 구축 (0) | 2024.04.14 |
| [아호코라식 (Aho-corasick) 알고리즘] 논문 이해하기 (1) - 검색 과정 (0) | 2024.04.12 |
| 편집 거리 알고리즘 이해하기 (0) | 2022.12.11 |


