상황
아래 로직을 구현한 코드가 flatMap 안에 flatMap 이 포함되어 있다. 코드 라인이 길고 들여쓰기가 많아서 가독성이 그리 좋지 않아 보인다.
1번 작업실행1번 작업결과가 0이면 에러 던지기1번 작업결과 후처리 (prefix변수에 저장)- 1번 결과 받아서
2번 작업실행 2번 작업결과가 0이면 에러 던지기- 2번 결과 받아서
3번 작업실행 1번 작업결과 +2번 작업결과 +3번 작업결과 더해서 반환
※ 각 작업은 1초 잠든 후 숫자를 반환한다.
public Mono<Integer> nestedFlatMap() {
AtomicReference<String> prefix = new AtomicReference<>("Prefix");
return _1번_작업()
.flatMap(firstResult -> {
if (firstResult == 0) {
return Mono.error(new RuntimeException("result is null"));
}
prefix.set(String.valueOf(firstResult));
return _2번_작업(firstResult)
.flatMap(secondResult -> {
if (secondResult == 0) {
return Mono.error(new RuntimeException("result is null"));
}
return _3번_작업(secondResult)
.map(result2 -> firstResult + secondResult + result2);
}
);
});
}
결과
public Mono<Integer> zipwhen_good() {
AtomicReference<String> prefix = new AtomicReference<>("Prefix");
return _1번_작업()
.filter(firstResult -> firstResult != 0)
.doOnNext(firstResult -> prefix.set(String.valueOf(firstResult)))
.zipWhen(this::_2번_작업)
.filter(result -> result.getT2() != 0)
.zipWhen(result -> _3번_작업(result.getT2()),
(result, result2) -> result.getT1() + result.getT2() + result2
)
.switchIfEmpty(Mono.error(new RuntimeException("result is null")));
}webflux 메소드를 사용해 한 줄로 표현하였다.
만약 tuple 을 getT1(), getT2() 로 가져오는 것이 직관적이지 않아 바꾸고 싶다면 번외를 참고해보자!
번외
tuple에서 getT1(), getT2() 안 쓰기
public Mono<Integer> zipwhen_tuple() {
AtomicReference<String> prefix = new AtomicReference<>("Prefix");
return _1번_작업()
.filter(firstResult -> firstResult != 0)
.doOnNext(firstResult -> prefix.set(String.valueOf(firstResult)))
.zipWhen(this::_2번_작업)
.filter(result -> function((_ignore, secondResult) -> secondResult != 0).apply(result))
.zipWhen(result -> function((_ignore, secondResult) -> _3번_작업(secondResult)).apply(result),
(result, result2) -> function((firstResult, secondResult, thirdResult) -> firstResult + secondResult + thirdResult)
.apply(result, result2))
.switchIfEmpty(Mono.error(new RuntimeException("result is null")));
}Functional Interface 를 활용해 getT1(), getT2() 대신 변수명을 보게 하였다.
그래서 코드 이해할 부분이 좀 더 많아지기 때문에 가독성이 뭐가 좋은지는 케이스에 따라 판단하자
function() 함수
public static <R> Function<Tuple2<Integer, Integer>, R> function(BiFunction<Integer, Integer, R> function) {
return tuple -> function.apply(tuple.getT1(), tuple.getT2());
}
public static <R> BiFunction<Tuple2<Integer, Integer>, Integer, R> function(Function3<Integer, Integer, Integer, R> function) {
return (tuple, v) -> function.apply(tuple.getT1(), tuple.getT2(), v);
}과정
(🌚실패) 첫 시도
public Mono<Integer> flatMap_doOnEach() {
AtomicReference<String> prefix = new AtomicReference<>("Prefix");
return _1번_작업()
.doOnEach(signal -> {
if (signal.get() == 0) { // NPE 발생!!
throw new RuntimeException("firstResult is null");
}
prefix.set(String.valueOf(signal.get()));
})
.flatMap(firstResult -> Mono.zip(Mono.just(firstResult), _2번_작업(firstResult)))
.doOnEach(signal -> {
if (signal.get().getT2() == 0) {
throw new RuntimeException("result is null");
}
})
.flatMap(result -> Mono.zip(Mono.just(result), _3번_작업(result.getT2())))
.map(result2 -> {
Integer first = result2.getT1().getT1();
Integer second = result2.getT1().getT2();
Integer third = result2.getT2();
return first + second + third;
});
}일단 flatMap 을 연속 호출하는 방법으로 바꿔보았다.
에러: 첫 doOnEach() 에서 signal.get() == 0 할 때 NPE 가 났다.
이유:
doOnEach()는_1번_작업()이 값을 방출할 때만 실행되는게 아니라doOnComplete시그널을 받을 때도 실행된다.doOnComplete시그널로 인해doOnEach()가 실행되면signal.get()은 null 이다._1번_작업()의 반환 값은 Mono 이다- null 의
intValue()를 호출할 수 없어서 NPE 가 난다.
해결: doOnNext() 로 바꾼다.
이 아래부턴 모두 성공하는 방법들이다!
(✅완성) 방법1 - flatMap()
public Mono<Integer> flatmap_doOnNext() {
AtomicReference<String> prefix = new AtomicReference<>("Prefix");
return _1번_작업()
.filter(firstResult -> firstResult != 0)
.doOnNext(firstResult -> prefix.set(String.valueOf(firstResult)))
.flatMap(firstResult -> Mono.zip(Mono.just(firstResult), _2번_작업(firstResult)))
.filter(result -> result.getT2() != 0)
.flatMap(result -> Mono.zip(Mono.just(result), _3번_작업(result.getT2())))
.map(result2 -> {
Integer first = result2.getT1().getT1();
Integer second = result2.getT1().getT2();
Integer third = result2.getT2();
return first + second + third;
})
.switchIfEmpty(Mono.error(new RuntimeException("result is null")));
}아래 작업이 한 줄로 매핑되어 읽기 쉬워졌다.
1번 작업실행:_1번_작업()1번 작업결과가 0이면 에러 던지기:.switchIfEmpty(..)1번 작업결과 후처리:.doOnNext(..)- 1번 결과 받아서
2번 작업실행:.flatMap(..) 2번 작업결과가 0이면 에러 던지기:.switchIfEmpty(..)- 2번 결과 받아서
3번 작업실행:.flatMap(..) 1번 작업결과 +2번 작업결과 +3번 작업결과 더해서 반환:.map(..)
리팩토링 요소: flatMap() 으로 반환할 때마다 이전 결과를 Mono.zip() 으로 감싸주는게 번거롭다
해결: zipWhen() 으로 바꾼다.
(🟡미완성) 방법2 - zipWhen()
public Mono<Integer> zipWhen_map() {
AtomicReference<String> prefix = new AtomicReference<>("Prefix");
return _1번_작업()
.filter(firstResult -> firstResult != 0)
.doOnNext(firstResult -> prefix.set(String.valueOf(firstResult)))
.zipWhen(firstResult -> _2번_작업(firstResult))
.filter(result -> result.getT2() != 0)
.zipWhen(result -> _3번_작업(result.getT2()))
.map((result) -> {
Integer firstResult = result.getT1().getT1();
Integer secondResult = result.getT1().getT2();
Integer thirdResult = result.getT2();
return firstResult + secondResult + thirdResult;
})
.switchIfEmpty(Mono.error(new RuntimeException("result is null")));
}flatMap vs. zipWhen
flatMap() 시절과 비슷하지만 Mono.zip() 으로 감싸주지 않았다는게 큰 차이점이다.
zipWhen() 은 첫번째 publisher 가 끝나고 두번째 publisher 실행도 끝나면 두 결과를 결합해 반환한다.
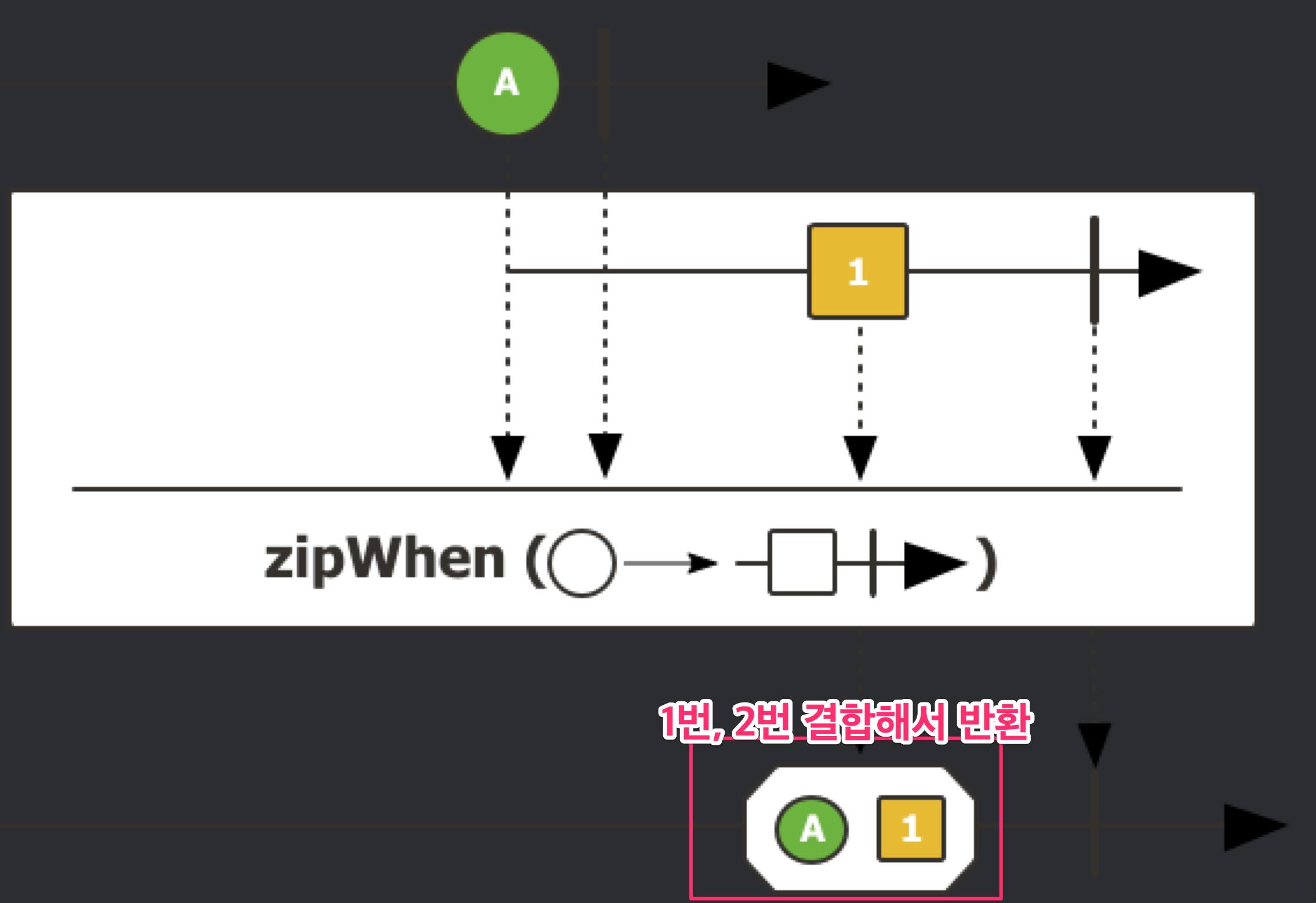

마블 다이어그램으로도 비교해보면 zipWhen 은 첫 번째, 두번 째 결과를 결합해 반환하지만 flatMap 은 마지막 결과만 반환하는 걸 확인할 수 있다.
zipWhen vs. zipWith
이름이 비슷한 두 함수 중 왜 zipWIth 를 쓰지 않았을까?
zipWith: 두 publisher 가 각각 실행하고 두 결과를 결합해 반환한다. (그래서 함께한다는 뜻으로 with가 붙은 것 같다)

zipWhen: 첫 번째 Publisher의 값을 기반으로 두 번째 Publisher를 실행한다. (그래서 1번이 끝나야 2번이 실행된다는 뜻으로 when이 붙은 것 같다)

1번 작업의 결과를 받아서 2번 작업을 실행해야하므로 zipWhen 이 더 적절하다.
리팩토링 요소: 마지막 라인의 zipwhen() 과 map() 을 합칠 수 있을 것 같다
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
(✅완성) 방법2 - zipWhen()
public Mono<Integer> zipwhen_good() {
AtomicReference<String> prefix = new AtomicReference<>("Prefix");
return _1번_작업()
.filter(firstResult -> firstResult != 0)
.doOnNext(firstResult -> prefix.set(String.valueOf(firstResult)))
.zipWhen(firstResult -> _2번_작업(firstResult))
.filter(result -> result.getT2() != 0)
.zipWhen(result -> _3번_작업(result.getT2()),
(result, result2) -> result.getT1() + result.getT2() + result2 // 여기
)
.switchIfEmpty(Mono.error(new RuntimeException("result is null")));
}zipWhen() 의 두 번째 인자로 합친 결과를 반환하는 로직을 구현할 수 있어 map() 을 대체할 수 있다.
리팩토링 요소: tuple을 .getT1(), .getT2() 으로 가져오는게 어떤 변수인지 명확하지 않아 가독성이 떨어진다.
해결: Functional Interface 로 해결해보자. 하지만 리팩토링을 한 로직이 코드가 좀 더 길어져서 트레이드 오프가 있을거같아 제목에 번외를 달았다.
(🟡미완성) 방법3 - zipWhen() + Tuple 리팩토링
public Mono<Integer> zipwhen_tuple() {
AtomicReference<String> prefix = new AtomicReference<>("Prefix");
return _1번_작업()
.filter(firstResult -> firstResult != 0)
.doOnNext(firstResult -> prefix.set(String.valueOf(firstResult)))
.zipWhen(firstResult -> _2번_작업(firstResult))
.filter(result -> function((Integer firstResult, Integer secondResult) -> secondResult != 0).apply(result))
.zipWhen(result -> _3번_작업(result.getT2()),
(result, result2) ->
function((Integer firstResult, Integer secondResult, Integer thirdResult) -> {
log.info("return complete: {}, {}, {}", firstResult, secondResult, thirdResult);
return firstResult + secondResult + thirdResult;
}
).apply(result, result2))
.switchIfEmpty(Mono.error(new RuntimeException("result is null")));
}function() 함수
public static <T1, T2, R> Function<Tuple2<T1, T2>, R> function(BiFunction<T1, T2, R> function) {
return tuple -> function.apply(tuple.getT1(), tuple.getT2());
}
public static <T1, T2, T3, R> BiFunction<Tuple2<T1, T2>, T3, R> function(Function3<T1, T2, T3, R> function) {
return (tuple, v) -> function.apply(tuple.getT1(), tuple.getT2(), v);
}io.projectreactor.addons:reactor-extra 의 TupleUtils.function() 에서 영감을 받았다.
Function3 클래스는 이 내용이다. ► git
function() 에서는 tuple 의 요소들을 파싱해 실행하고픈 로직의 파라미터로 넣어주는 Function 을 만들어준다.
리팩토링 요소: (Integer firstResult, Integer secondResult, Integer thirdResult) 처럼 데이터 타입을 일일히 넣어주니 코드가 너무 길어진다
해결: 제네릭이 아닌 데이터 타입을 직접 명시해주자
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
(✅완성) 방법3 - zipWhen() + Tuple 리팩토링
public Mono<Integer> zipwhen_tuple() {
AtomicReference<String> prefix = new AtomicReference<>("Prefix");
return _1번_작업()
.filter(firstResult -> firstResult != 0)
.doOnNext(firstResult -> prefix.set(String.valueOf(firstResult)))
.zipWhen(firstResult -> _2번_작업(firstResult))
.filter(result -> function((_ignore, secondResult) -> secondResult != 0).apply(result))
.zipWhen(result -> function((_ignore, secondResult) -> _3번_작업(secondResult)).apply(result),
(result, result2) ->
function((firstResult, secondResult, thirdResult) -> firstResult + secondResult + thirdResult)
.apply(result, result2))
.switchIfEmpty(Mono.error(new RuntimeException("result is null")));
}
public static <R> Function<Tuple2<Integer, Integer>, R> function(BiFunction<Integer, Integer, R> function) {
return tuple -> function.apply(tuple.getT1(), tuple.getT2());
}
public static <R> BiFunction<Tuple2<Integer, Integer>, Integer, R> function(Function3<Integer, Integer, Integer, R> function) {
return (tuple, v) -> function.apply(tuple.getT1(), tuple.getT2(), v);
}function() 에서 데이터 타입을 명시해주었다. 이제 함수 호출할 때 데이터타입을 안 써도 된다.
► 깃 확인하기
레퍼런스
https://tolkiana.com/avoiding-nested-streams-spring-webflux/
https://techblog.woowahan.com/12903/
https://yeonyeon.tistory.com/327
https://d2.naver.com/helloworld/2771091
https://jehuipark.github.io/java/java-conditional-operator
글 읽어주셔서 언제나 감사합니다. 좋은 피드백, 개선 피드백 너무나도 환영합니다.
'SearchDeveloper > Java' 카테고리의 다른 글
| 테스트 클래스 다른 모듈에서 공유하기 (0) | 2025.12.30 |
|---|---|
| ListenableFuture 의 Callback Hell 해결하기 (0) | 2023.05.03 |
| [JPA] 영속성 컨텍스트(Persistence Context) : 엔티티 관리 공간 (0) | 2022.10.03 |
| Java 애플리케이션 메모리 누수(Memory leak) 잡기 - jstat, MAT (0) | 2022.10.02 |
| Java 에서 테스트용 도커 컨테이너 띄우는 법 : TestContainer (4) | 2022.06.21 |



