https://woowacon.com/presentations
WOOWACON 2023
한 번의 배달을 위해 필요한 모든 기술들
woowacon.com
2023년 11월 15일 수요일, 우아콘 2023에 참가하여 백엔드 기술에 대한 다양한 이야기들을 들었다.
내가 들은 세션들은 주로 점점 증가하는 대규모 트래픽에 대응하기 위해 이러이런것을 했어요를 소개하는 내용이었다.
세션을 진행한 팀은 다르지만 조회와 처리 이벤트를 분산하기 위해 CQRS 를 적용했다는 점, 이벤트 순서가 꼬이거나 발행을 실패했을 때를 대비하기 위해 Transaction outbox pattern 를 적용했다는 점을 공통으로 적용하고 있었다.
올해 '데이터 중심 애플리케이션 설계' 책을 힘겹게 정리해가면서 완독했지만 주로 이론적인 내용이라 실무에 적용할 일이 있을까 싶었는데 이번 세션들에서 결과적 일관성, 스트림 조인 같은 책에서 봤던 용어들이 나와서 뭘 공부하든 언젠가는 도움이 되는구나를 깨달았다.
예전에 이런 세미나를 들을 때는 직접 구현된 내용을 못 봐서 약간 뜬 구름 잡듯이 느껴졌는데, 이 회사에 이직하고 나서 보고 들은 것을 떠올리면서 세션들을 들으니 이해가 좀 더 잘됐다. 유용한 시간이었다!

대규모 트랜잭션을 처리하는 배민 주문시스템 규모에 따른 진화
배민주문시스템의 성장통이 무엇이었는가
1.단일 장애 포인트 - 하나의 시스템이 전체 시스템의 장애로 이어진다
이전에는 두 세개 팀이 중앙저장소 루비를 갖고있어서 루비 에러나면 전체 에러였지만,

지금은 각 팀마다 저장소 구비하고, 팀간에는 MQ 로 이벤트를 발행해 느슨한 결합으로 구성함.
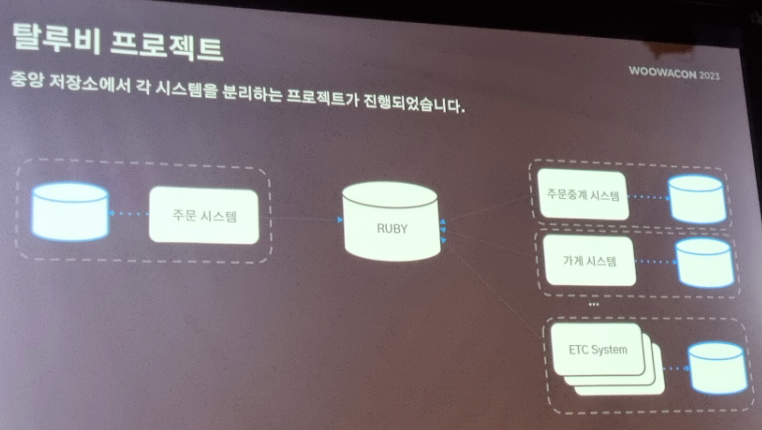
2.대용량 데이터 - RDMS 조인 성능이 좋지 않음
주문 시스템 아키텍처에서 주문 DB 를 사용하는데, 조회와 주문 이벤트 처리 를 같은 DB 를 사용하고 있었다.
주문 + 결제 + 메뉴 정보등 애그리거트를 많은 JOIN 연산으로 처리하다보다 성능저하가 발생했다.
몽고DB 로 바꿨다. 주문 당 문서 하나 생성. 역정규화로 한 문서에 모든 정보 집어넣음
→ CQRS 아키텍처 적용

3.대규모 트랜잭션 - 저장소의 쓰기 처리량 한계 도달
장비 최고 스펙으로도 쓰기 한계가 있었음
조회쪽은 리더가 스케일아웃하면 됐는데
주문 처리 쪽은 프라이머리 하나라 스펙업밖에 할 수 없었고 고민을 하게 됨

해결: 프라이머리 샤딩으로 하려했지만 오로라는 샤딩을 지원하지 않음. 그래서 코드단에서 샤딩 전략을 적용시키기로 함
샤딩 전략 3가지 중 하나를 정해야 했었음
- 1.Key based sharding: 샤드 키(주문번호) 를 해싱한 값으로 샤딩하자
- 2.Range based sharding: 가격 범위 기반으로 샤딩하자
- 3.Directorybased sharding: 이 키는 어디 샤드로 갈지 중간에 look up table 을 둔다.
3개 중 뭘로 정할까..
- 주문시스템은 주문이 정상 동작하는게 중요하다. → 단일 장애 포인트는 피하자
- 주문 취소는 최대 30일까지 가능해서 주문 데이터는 최대 30일까지만 저장한다. → 샤드 추가 이후 30일이 지나면 균등하게 분배된다. 데이터가 없어지니까.
프라이머리 DB 는 여러개 두고, 각 DB 에 코드단에서 샤딩하여 저장하는 방식임

4.복잡한 이벤트 아키텍처 - 규칙 없는 이벤트 발행으로 서비스 복잡도가 높아짐
도메인 로직(주문관련) 과 서비스 로직(현금영수증 발행 등)을 분리함
단점: [1]주문 취소, 현영 취소는 주문 배치라는 다른 시스템에서 해야함, [2]스프링 이벤트를 사용하다보니 재발행할때 어려움
[1] 중간에 sqs 를 넣고 추가 데이터 넣는거는 각각 필요한 외부 시스템에서 채워넣는걸로함
[2]이벤트 발행시 실패했을 때?
- 트랜잭션 내 이벤트 발행이 실패하면 도메인 전체가 실패하기 때문에 알 수 있음
- 트랜잭션 외에서 이벤트 방핼 실패하면 동기화가 안 돼서 알 수 없음
- 해결: 트랜잭션 내 OUTBOX 엔티티를 줘서 이벤트 실패시 다시 가져갈 수 있도록 함. → 이벤트 중복은 가능하나 유실은 없게(at-least once) 설계
아키텍처
- 이벤트 기반으로 하고 있다.

추천시스템 성장 일지: 데이터 엔지니어 편
=데이터사이언티스트 + 데이터엔지니어(3명) + PM
1.데이터사이언티스트가 모델 개발에 하는 일 수행
2.추천 데이터 생성하는 일 함
2.추천 데이터 생성하는 일 함
학습 후 오프라인 예측 - 미리 추천 결과를 생성해둠
- 배민, 배달홈 개인화 추천에 사용
- EKS 의 airflow 로 학습 데이터를 생성해서 s3 에 저장됨, 하이브로 관리 (EMR on EKS)
- gpu로 학습에서 모델을 s3 에 저장함
- 어떤 사용자가 어떤 가게를 좋아할지 추천 결과를 생성해서 s3 에 저장함
- API 가 쉽게 조회할 수 있게 spark 로 몽고DB 에 업로드
학습 후(모델 생성 후) 온라인 예측 - 실시간으로 모델 추론
- 비마트 장바구니 (장바구니 진입 시점에 예측) 에 사용
- EKS 의 airflow 로 학습 데이터를 생성해서 s3 에 저장됨, 하이브로 관리 (EMR on EKS)
- gpu로 학습에서 모델을 s3 에 저장함
- 장바구니 뷰, 클릭, 상품 정보 같은 피쳐 정보를 생성해서 s3 에 저장함
- 피쳐 데이터를 몽고디비에 업로드함
- 추천 API 요청하면 피쳐데이터를 들고와서 모델 때려서 결과 가져옴
추천 결과를 앞쪽 서버(전시, 리스팅 서버) 에 전달하는 방법
- DB 에 올려준다. 사용자, 추천 가게, 추천 점수
- 초반에 많이 사용했다. 장점: 간단하고 편함. 단점: 작업이 변경되면(포맷바꾸거나) 타팀 의존성이 생김(타팀과 맞춰야해서), DB 에 대한 의존성이 생김
- 해결: API 를 통해 꼭 필요한 정보만 주고받자
- 언제든지 배포가능, 추천 정보를 내부에서만 가져갈 수 있음, 실험정보를 로깅해서 a/b 테스트 유용
컨테이너화 & 쿠버네티스 도입
기존 환경
- IDC GPU 서버에서 학습 데이터 다운, 아나콘다로 모델 학습, 업로드
- airflow 에서 학습 요청 날려야 해서 SSHOPERATOR 로 커맨드 날림
- 단점: GPU 서버를 같이 쓰다보니 자꾸 에러 발생하고 다른 학습중인 모델 킬하기도 함 / 실행환경 버전을 같이 쓰다보니 관리하기가 어려움
변경: 쿠버네티스 파드 환경
- ID 쿠버네티스 클러스터 서버에서 학습 데이터 다운, 아나콘다로 모델 학습, 업로드
- airflow 에서 학습 요청 날려야 해서 KubernetesPodOperatior 로 처리
- 장점: GPU 서버 접속할 일이 줄어듦, 리소스 부족해서 학습 중단되는거 줄어듦 / ML 의 FastAPI 같은 다양한 서비스를 쉽게 사용할 수 있는 환경 구성해줌
실시간 데이터는 어떻게 받아올까?
실시간의 종류
-실시간으로 모델을 추론한다.
-실시간으로 데이터를 취득한다. (데이터 파이프라인으로)
- 이거에 대해!
- 방금 본 상품과 비슷한 상품 같은 ‘방금' 서비스 가능
- 방금 본 상품 리스트를 타팀이 API 로 전달해주는 문제라면..
- 타팀에게도 API 부하 있음, 의존성 생김, 방금의 기준같은 정책이 달라지면 의존성 생김
- 해결: 직접 데이터를 가져온다. 앱로그를 카프카에 넣고 몽고디비에 실시간 피쳐 스토어에 넣는다.
- 실시간 상품 API 요청이 들어오면 방금 본 상품 데이터는 몽고디비에서 가져온다. 타팀은 사용자만 알려주면 된다.
EKS
데이터 엔지니어 3명은 EKS 운영 경험이 없다. 마침 옆팀(데이터플랫폼팀)에서 운영중
EKS 타팀꺼 쓸까 아니면 우리가 직접 할까? 데이터플랫폼에 올라타자! 우선 올라타고 문제 생기면 나누자
Kafka를 활용한 이벤트 기반 아키텍처 구축
이벤트 기반 아키텍쳐
- 결과적 일관성 → 이벤트 기반으로 구현하면 배달이 변경되었을 때, 통계나 쿠폰 등 시스템에서 언젠가 반영만 되면 된다.
- 이벤트란? 도메인에 영향을 주는 관심 정보: 대상, 발생 시간, 행동 → 배달에서 발생한 행동을 알려주고 싶어
sqs 보다 카프카 선택함
- 순서보장: 키를 기반으로 같은 파티션에 들어가니까 순서보장됨
- 고성능, 고가용성: 페이지캐시, 클러스터 관리. Kafka Streams, Kafka Connect 등 통합 도구 제공
- 한 프로듀서와 한 컨슈머를 매핑함
- 단점: EBS 이슈, 등으로 재시도 하면서 이벤트 순서가 달라지는 경우 발생.
- sqs 는 동시에 발생한 이벤트는 순서 보장이 안될수도 있다!
- 해결: Transaction outbox pattern 도입
- 이벤트 기반에서 많이 사용하는 패턴
- 프로듀서가 DB 에 이벤트를 발행하고, 트랜잭션 완료되면 중간에 Message Relay 에 넣고, 이 데이터가 컨슈머로 흘러감
- Message Relay 로 debezium 을 선택. 메시지 저장하고 카프카에 넘겨줌. CDC 에서 많이 사용. DB 의 바이너리 로그 읽어 이벤트 순서를 보장해줌
- 내부에 키와 이벤트를 매핑한 테이블이 있음
CQRS 적용해 커맨드와 조회 저장소 분리함
Kafka Streams를 활용한 이벤트 스트림 처리 삽질기
스트림 처리를 배치 처리 대신 택했다.
Apache Flink 와 Kafka Streams 두 개를 고민했다.
- Kafka Streams : 자바 앺에 포함 가능한 라이브러리
- Apache Flink: 독립적은 클러스터 프레임워크

스트림 조인

-파티션 너무 많으면 성능 저하 올 수 있으므로 파티션 수 유지하는 방향으로 생각하라
-토픽 하나에 통으로 넣지 말고 여러 토픽에 분산시켜라
-컨슈며 lag 이 임계치 넘지 않도록 관리. 이때 서버 증설은 한계가 있으므로 스레드 수를 조절함
-파티션이나 컨슈머에 변화가 있을 때, 파티션의 데이터를 컨슈머에게 균등하게 분배하기 위한 리밸런싱 - 고비용 작업
-브로커가 컨슈머 그룹 모니터링하고 지연이 크면 탈락 시킨다. 관련 설정값을 잘 조정한다.Leave 로그가 있는지 확인한다.
-리파티셔닝 남용하지 말자. 키를 바꾸면 이벤트가 파티션을 이동하는데 이 때 큰 부하가 일어날 수 있다.
-모니터링툴: Burrow
'SearchDeveloper > 기타' 카테고리의 다른 글
| opencode 튜토리얼 - LLM모델을 CLI에서 사용하기 (0) | 2025.10.10 |
|---|---|
| Azure OpenAI 사용법 튜토리얼 (0) | 2023.07.01 |
| Kafka-ui 설치하기 (Docker 말고) (0) | 2023.02.24 |
| 텔레그램 봇으로 메시지 전송 API 호출하기 (0) | 2022.12.06 |



