부호화와 발전
: 데이터 부호화를 위한 다양한 형식을 살펴본다.
데이터 스키마가 바뀌면 상위호환, 하위호환은 어떻게 하는지 알 수 있다.
웹서비스나 메시지 큐에서 부호화 형식이 데이터 저장, 통신에 어떻게 쓰이는지 알 수 있다.
시스템은 호환성이 유지될 수 있어야한다.
※ 호환성: 이전 버전과 새 버전의 데이터가 공존해도 시스템은 정상적으로 돌아가는것
관계형 DB 같이 쓰기 시점에 스키마가 정해지는 쓰기 스키마와 다르게 읽기 스키마(schemaless) 는 스키마를 강요하지 않으므로 한 컬렉션 안에 새로운 버전과 이전 버전의 데이터타입이 섞여들어갈수있다.
근데 애플리케이션 단에서는 새 버전에 대한 대응 코드를 즉시 반영할 수 없다. 왜?
- 서버 단: 대규모 시스템에서는 트래픽 처리를 위해 여러 개 서버군이 한 역할을 하는데 여기서 무중단 배포를 위해서 이전 버전 서버, 새 버전 서버가 공존할수밖에 없다.
- (elsboo) 무중단 배포 전략 - 롤링, 블루/그린, 카나리(https://hudi.blog/zero-downtime-deployment/) (블루그린도 독립적인 환경이긴 하지만 배포 전 테스트는 해야하니 공존해야하는 상황은 존재한다)
- 클라 단: 업데이트는 사용자의 선택에 좌우된다. 앱을 사용자가 업데이트 할수도있고 안할수도 있으니깐
그렇기 때문에 새로운것과 이전의 데이터 타입이 공존할 수 있도록 호환성을 잘 유지할 수 있어야 한다.
(elsboo) 예시) 사용자가 등록한 게시글을 DB 에 저장하는 프로그램이 있다. 좋아요 필드가 추가되었다.
- 하위 호환성: (위 → 아래) 새 코드는 예전 코드가 기록한 데이터를 읽을 수 있어야 한다.
- (elsboo) 좋아요 데이터가 없을 옛날 데이터도 정상적으로 읽어야한다.
- 상위 호환성: (아래 → 위) 예전 코드는 새 코드가 기록한 데이터를 읽을 수 있어야 한다.
- (elsboo) 좋아요 데이터가 있는 새 데이터도 예전 코드가 정상적으로 읽어야한다.
데이터 부호화 형식
※ 부호화: 다른 시스템에세도 데이터를 이해할 수 있도록 표현 방식을 바꿔주는거
❓ 원래 데이터는 어떻게 생겼길래 표현 방식을 바꿔줘야하는거지?
❗ 원래 데이터는 메모리에 저장되어있다. 객체, 배열, 해시테이블, 트리 등으로 데이터가 유지되어있고 cpu에서 호율적으로 접근하기 위해 보통 포인터로 구성된다. 근데 이런 포인터를 네트워크로 전송하면 딴 시스템은 못알아들을 것이므로 일련의 바이트열(ex. 1110101010) 로 변환해서 보내야 한다. (인메모리 표현 → 바이트열로 전환)
=> 메모리를 공유하지 않는 다른 프로세스로 데이터를 보내고 싶을 때 바이트열로 부호화해서 보내야함
❓ 어떤 표현 방식이 있지?
❗ JSON, XML, 프로토콜 버퍼, 스리프트(Thrift), 아브로(Avro)
용어정리
인메모리 -> 바이트열: 부호화(직렬화, 마샬링)
- (elsboo) 직렬화: 자바 객체를 바이트로 / 마샬링: Object를 XML string 으로
바이트열 -> 인메모리: 복호화(파싱, 역직렬화, 언마샬링) - (elsboo) 역직렬화: 바이트를 자바 객체로 / 언마샬링: XML string을 Java Object로
언어별(자바, 파이썬, 루비 등)로 부호화 기능을 제공하지만 문제점이 많다
- 해당 언어에 의존적이기 때문에 그 언어로만 작성해야하고 다른 언어를 사용하는 시스템과 통합하는데 방해가 된다.
- 보안 리스크 - 공격자가 바이트열을 복호화하게 되면 임의의 클래스를 인스턴스화하수있고 그럼 임의의 코드도 실행할 수 잇다.
- 버전관리가 잘 안돼서 상위 호환 하위 호환할 때 불편한가보다
- 효율성(부호화, 복호화 하는데 걸리는 시간, 부호화된 구조체 크기) 도 별론가 보다. 자바 직렬화도 느리고 사이즈가 커진다 한다.
- (elsbo) java serialization 성능 별로지만 FST 같은 대안에 대한 글 (https://www.alibabacloud.com/blog/an-introduction-and-comparison-of-several-common-java-serialization-frameworks_597900)
=> 그럼 대안은? JSON, XML, CSV, 이진 변형
- (elsbo) java serialization 성능 별로지만 FST 같은 대안에 대한 글 (https://www.alibabacloud.com/blog/an-introduction-and-comparison-of-several-common-java-serialization-frameworks_597900)
JSON, XML, CSV 는 human readable 이지만 미묘한 단점
- 숫자 타입 표현 어려움. xml, csv 는 못하고 json 은 숫자와 문자열을 구분할순있지만 정밀한 소수점은 표현하기 어렵다.
- 이진 문자열 (문자부호화 없는 바이트열) 을 지원하지 않아 이진데이터를 Base64를 사용해 텍스트를 부호화해 이런 제한을 피한다. Base64로 부호화됐기 때문에 해석해줘야한다. ???
- XML, JSON 은 스키마를 지원하지만 강제하진않고 스키마 정보에 따라 올바른 해석이 다르기 때문에 JSON, XML 스키마를 사용하지 않은 애플리케이션은 하드코딩으로 부호화/복호화 작업을 해줘야한다.
- csv 는 스키마가 없어서 애플리케이션단에서 명시해야하고 컬럼 변경되면 수동으로 코드도 바꿔줘야하고 쉼표나 개행 처리가 모호하다. 처리 규칙은 있지만 모든 파서가 지키지는 않는다.
=> 이렇게 단점이 있어도 타 조직 간의 데이터 교환 형식으로 충분하기 때문에 많이 쓰일것이다.
이진부호화
(elsboo) ? 이진부호화는 데이터를 0,1로 부호화한다는 뜻인가
JSON, XML 은 이진 형식에 비해 훨씬 많은 공간을 차지한다.
JSON 용 이진 부호화(메시지팩, BSON 등) 방식이 있지만 JSON 텍스트 만큼 널리 채택되진 않았다.그리고 데이터 모델은 유지 하기 때문에 객체의 모든 필드 이름도 포함해야 한다.
부호화할 예제 json text

messagePack 으로 인코딩하면: 66byte
messagePack: JSON용 이진 부호화 형식

필드명, 값, 문자열 길이 정보, 데이터 타입 정보 포함
https://moo-you.tistory.com/329(10진수 / 16진수 / 2진수 변환표)
Apache Thrift(페이스북), Protocol buffer(구글)


스리프트: 바이너리 프로토콜(59byte), 컴팩트 프로토콜(34byte)
바이너리 프로토콜(59byte)
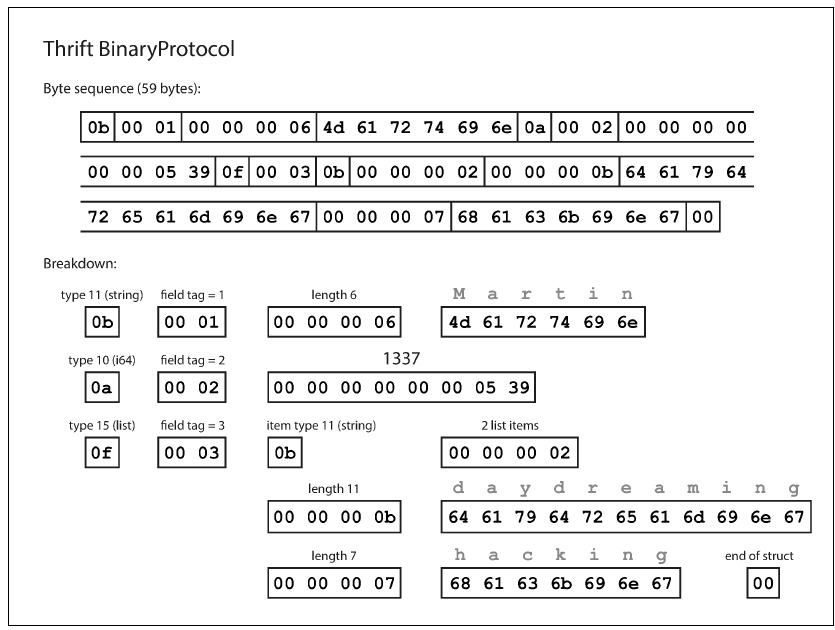
컴팩트 프로토콜(34byte)

프로토콜 버퍼 (33byte)

필드 추가/변경/삭제 됐을 때 호환성을 유지하는 방법
스리프트, 프로토콜 버퍼
필드 추가/삭제
데이터타입 변경
리스트와 단일 필드간의 변경
- 상위 호환: 예전 버전에서 새 데이터를 읽을 수 있어햐 함 -> 단일 필드이니 마지막 요소만 보면 됨
- 하위 호환: 새 코드는 예전 데이터를 읽을 수 있어야함 -> 새 코드는 리스트이므로 0개나 1개로 간주하여 읽으면 됨
아브로(Apache Avro)
- IDL(Avro IDL) : 사람이 편집하는
- JSON기반 : 기계용

아브로 32byte
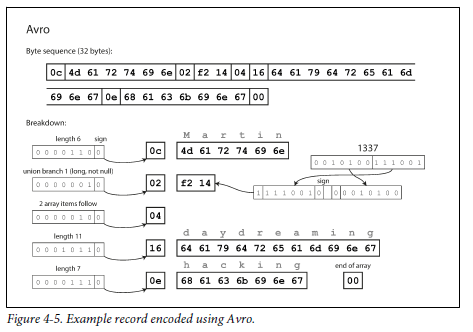
스키마 변경(발전)은 어떻게 지원?

스키마 발전하려할 때 지켜야 하는 규칙
- union {null, long} field 처럼 여러 data type 을 가지는 타입
읽기 입장에서는 어떤 쓰기 스키마로 데이터를 부호화했는지 알 수 있을까?
아브로 장점: 동적 생성 스키마
스키마가 있으면 좋은 점
다른 프로세스간의 데이터를 전달하는 방법 3가지
1. DB 를 통해
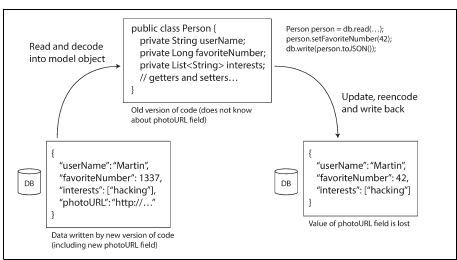
스키마 발전
2. 서비스 호출을 통해 (REST, RPC)
- 원격 네트워크 서비스 요청을 특정 함수나 메소드 호출하는 것과 동일하게 사용가능하게 해주는것
- 네트워크 통신은 예측이 어렵기 때문에 다음을 고려해야 한다.
3. 메시지 전달을 통해
- 수신자가 사용 불가능할 경우 메시지를 저장하는 버퍼처럼 동작하기 때문에 시스템 안정성이 향상된다.
- 송신자가 수신자에 대해 알 필요가 없다.
- 하나의 메시지를 여러 수신자에게 전송할 수 있다.
- 논리적으로 송신자와 수신자가 분리돼서 publisher는 consumer 가 누군지 신경쓰지 않아도 된다.
구조
PART2 분산 데이터
일단 여러 장비가 필요한 이유
- 부하가 커졌을 때 장비를 추가해 확장성을 확보할 수 있다.
- 서버 하나가 실패해도 다른 하나가 이어받는 내결함성/고가용성을 보장할 수 있다.
- 세계 여러 곳곳에 서버가 존재하면 사용자 지역 근처의 서버와 통신하면 되므로 지연시간을 줄일 수 있다.
데이터 분산하는 방법 2가지
- 복제(리플리카): 복사본을 다른 노드에 위치시켜 한 노드에 장애났을 때 다른 노드의 복사본으로 서빙할 수 있다. 성능향상에도 도움된다는데 5장에서 알아보겠다.
- 파티셔닝(샤딩): 큰 데이터를 작은 단위의 파티션으로 나누고 다른 노드에 각각 저장한다. 6장에서 알아보겠다.

레퍼런스
데이터 중심 애플리케이션 설계
'SearchDeveloper > 데이터 중심 애플리케이션 설계' 카테고리의 다른 글
| [6] 파티셔닝 하는 방법, 리밸런싱 전략, 요청 라우팅 전략 (0) | 2023.07.01 |
|---|---|
| [5] 복제를 구성하는 방법과 동기화를 위한 노력 (0) | 2023.06.25 |
| [3] DB가 데이터를 어떻게 저장하고, 질의하면 데이터를 어떻게 찾을까? (1) | 2023.05.31 |
| [2] 어떤 데이터 모델을 어떤 경우에 쓰면 좋을까? (0) | 2023.05.15 |
| [1] 데이터를 중심으로 하는 애플리케이션은 어떤 걸 생각해봐야할까? (2) | 2023.05.06 |



