3장에서 알려줄거: DB가 데이터를 어떻게 저장하는지, 질의하면 데이터를 어떻게 찾는지
→ 개발자가 내부 구현을 알아야하는 이유는 적합한 DB를 선택하기 위해서!
색인에 대해
기본 데이터에서 파생된 추가적인 메타데이터이다.
색인이 필요한 이유는 질의 성능이 좋아지기 때문이다.
하지만 데이터를 쓸 때마다 색인에도 갱신해야 하기 때문에 쓰기 속도는 색인을 사용하지 않는 경우보다 느리다.
그래서 모든 데이터를 색인하지 않고 필요한 데이터만 수동으로 색인을 선택한다.
해시 색인
: 메모리에 키-값 형태로 저장
디스크에 색인 데이터가 계속 증가된다면 이걸 읽는 메모리는 결국 모자라게 되겠지 이 때 해결책은 컴팩션(compaction)!
디스크 공간 부족 해결 - 컴팩션
컴팩션 이란?
- 로그에 중복된 키는 버리고 제일 최근 값 하나만 저장
- 세그먼트 파일은 수정될 수 없기 때문에 병합할 때 새 파일로 만드는 것이다.
- 백그라운드에서 실행하므로 컴팩션 동안은 기존 세그먼트 파일로 읽기 쓰기 요청 처리 가능하다.
- 병합이 끝나면 새 세그먼트를 바라보게 한 후 이전 세그먼트는 삭제한다.
컴팩션 하기
- 로그를 특정 크기의 세그먼트로 나눈다.
- 세그먼트 파일에 계속 쓰다 특정 크기 도달하면 새로운 파일에 쓰는데, 이 때 컴팩션을 거친 후 쓴다.
구현 시 고려해야 할 것
- 파일 형식: csv 보다는 바이너리 형식이 빠르고 간단하다.
- 레코드 삭제: 레코드가 삭제되면 툼스톤(tombstone, 묘비)파일에 기록 한다.
- (elsboo): ES 도 문서 삭제 요청 시 바로 삭제하지 않고 태깅만 한다. 병합할 때 진짜 디스크에서 삭제된다.
- 고장 복구: DB가 재시작되면 인메모리 해시 맵은 손실되므로 빠르게 재로딩할 수 있게 스냅숏을 디스크에 저장한다.
- 부분적으로 레코드 쓰기: DB 가 로그에 레코드 쓰는 도죽에 죽는다면 체크섬을 활용해 손상을 탐지해 무시한다.
- 동시성 제어: 쓰기 스레드는 하나만 사용한다. 읽기는 추가를 제외하면 불변이므로 멀티 스레드 가능하다.
(elsboo) 카프카에서도 컴팩션 모드가 있다. 일정 주기로 동일한 키 중 가장 최근 이벤트만 들고 있을 수 있다. 이벤트 수를 줄일 수 있다는 장점이 있다.

해시 색인 단점
- 키가 너무 많을 때 문제가 된다. 메모리에 저장하다니 터질 수도있고 디스크에 저장하자니 성능을 기대하기 어렵기 때문이다.
- range query 처리가 어렵다. 1~9 범위를 검색 시 모든 키를 조회해야한다.
SS(Sorted String) 테이블과 LSM (Log Structured Merge) 트리
- 키-값 구조를 키로 정렬하는 게 해시 색인과 다른 점이다!
- 키는 병합된 세그먼트 내에 한 번만 출현해야한다. (컴팩션으로 보장)
- 장점: 정렬돼있기 때문에 키가 1~10까지 있다면 메모리에는 1,5,10 만 올려(희소 색인, spare index) 메모리 공간 사용을 줄일 수 있다.
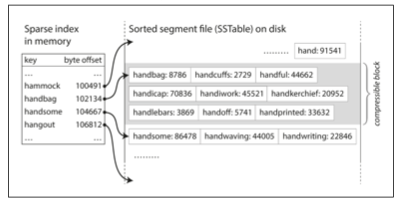
새로운 키가 들어왔을 때 정렬하는 법
1. 쓰기가 들어오면 인메모리 균형 트리 데이터 구조(ex. red-black tree, AVL tree)에 추가한다.
- 멤테이블(memtable) 이라고 부른다. ((memory 에 있어서 mem 테이블인가봄!))
2. 멤테이블이 특정 크기보다 커지면 SS 테이블 파일로 디스크에 기록한다.
- 이미 멤테이블에 키가 정렬돼있기 때문에 SS 테이블로 용이하게 바꿀 수 있다.
- 새로운 SS 테이블이 가장 최신 세그먼트가 된다.
- 기록 작업동안 추가되는 키는 새로운 SS 테이블 파일에 작성된다.
3. 가끔 병합과 삭제된 값 버리는 컴팩션 과정을 백그라운드에서 수행한다.
→ 읽기 요청이 들어오면 먼저 멤테이블에서 키를 찾고, 그 다음 디스크의 최신 세그먼트에서 부터 찾는다.
→ DB 가 고장나면 메모리에 저장된 멤테이블은 삭제될 수 있으므로 로그를 바로 디스크에도 쓴다. 이 파일은 복원할 때만 사용하고 멤테이블을 SS에 기록하면 해당 로그는 버린다.
(elsboo) ES 도 비슷하게 동작한다. 새 문서를 색인하면 직후엔 메모리에 작성한다. 그 후 일정 시간이 지나면 디스크에 루씬 세그먼트 파일로 옮겨지는데, 그 전에 메모리 데이터가 유실될 수 있으므로 translog 에도 작성해서 유실 시 사용한다. 디스크에 쓰이고 나면 트랜스로그는 삭제된다.
LSM 저장소 엔진
- 정렬된 파일 병합과 컴팩션 원리를 기반으로 하는 저장소 엔진
- 루씬 색인도 텀과 ID 매핑은 SS테이블 같은 정렬 파일에 유지하고 백그라운드에서 병합한다.
성능 최적화
- 문제: LSM 트리 알고리즘은 미존재하는 키를 찾을 때 키를 처음부터 끝까지 탐색해야하기 때문에 느리다.
- 해결: Bloom filter 를 사용하면 DB에 존재하지 않음을 알려주므로 읽기 과정을 줄일 수 있다.
- (elsboo) bloom filter: 정확히 이해는 못 했으나 해시 함수로 반환된 값을 비트 단위로 비교해 있다 없다 판단하는 것 같음
- 해결: Bloom filter 를 사용하면 DB에 존재하지 않음을 알려주므로 읽기 과정을 줄일 수 있다.
- SS 테이블을 압축하고 병합하는 순서와 시기 결정 가능
- LSM 트리 개념 자체가 효율적이다
- LSM트리: 백그라운드에서 연쇄적으로 SS 테이블을 지속적으로 병합
LSM 트리 장점
- B트리보다 쓰기 증폭이 낮다.
- 쓰기 증폭(write amplification): DB 쓰기 한 번이 쓰기전로그나 컴팩션, 병합 때문에 디스크에 여러 번 쓰기를 야기하는 효과
- 자기 HDD는 순차쓰기가 임의 쓰기보다 훨씬 빠른데, LSM 은 컴팩션된 SS 테이블을 순차 쓰기하고 B트리는 여러 번 덮어쓰는 임의 쓰기를 한다.
- 압축률이 더 좋다.
- B트리보다 디스크에 더 적은 파일을 생성한다. 왜? B트리는 페이지 단위이기 떄문에 페이지 파편화로 인해 공간 일부가 남는데 LSM은 페이지 단위도 아니고 파편화를 없애기 위해 SS테이블을 다시 기록하기 때문이다.
→ SSD 는 내부 에서 임의쓰기를 순차쓰기로 전환하기 위해 내부적으로 로구 구조화 알고리즘을 쓰기 때문에 저장소 엔진의 쓰기 패턴에 크게 영향을 미치진 않지만 낮은 쓰기 증폭과 파편화 감소는 훨씬 유리하다.
LSM 트리 단점
- 컴팩션 과정이 오래 걸리면 진행중인 읽기/쓰기 성능에 영향을 줄 수 있다. 디스크 자원은 한계가 있기 때문에 컴팩션 끝날때까지 요청받은 읽쓰가 대기탈 수 있기 때문이다.
- 높은 쓰기 처리량. 백그라운드에서 수행하는 초기 쓰기, 멤테이블 디스크로 방출(flushing), 컴팩션 쓰레드와 디스크 대역폭을 공유해야한다.
- 컴팩션과정이 들어오는 쓰기 속도를 못 따라갈 수 있다. 그럼 세그먼트는 디스크가 부족할 때까지 증가하고 읽을 때도 더 많은 세그먼트를 확인해야하기 때문에 읽기 속도도 느려진다.
- 다른 세그먼트에 키가 같은 다중 복사본이 존재할 수 있다. B트리는 키가 색인의 한 곳에만 정확하게 존재하는데 말이다.
B트리
- 가장 널리 사용되는 색인 구조
► 로그 구조화 색인 (Log Structured) : 수 MB 이상의 가변 크기 세그먼트로 나누고 순차적으로 기록한다
► B 트리: 4KB 정도의 고정 크기 블록이나 페이지로 나누고 한번에 한 페이지에 읽/쓰 한다.
- 디스크가 고정 크기 블록이기 때문에 하드웨어 설계와 관련.
- 페이지: 디스크의 포인터 같은 거. 주소나 위치를 이용해 식별할 수 있다. 한 페이지가 다른 페이지를 참조할 수 있다.

- 페이지의 참조를 따라가고 있다.
새 데이터는 디스크 페이지에 덮어쓴다
그렇기 때문에 신뢰할 수 있게 하는 추가 작업이 필요하다
- 쓰기 전 로그(write-ahead log, WAL = redo log) : 변경 내용 적용 전 모든 B 트리 변경사항을 기록하는 파일. 복구할 때 사용한다.
- 동시성 제어 필요: 래치(latch) 라는 가벼운 잠금으로 데이터 보호
B 트리 최적화
- 위에서 말한 쓰기 전 로깅 방법 대신 쓰기 시 복사 방식 (copy-on-write scheme) 를 사용한다. 변경된 페이지를 다른 위치에 기록해 그 위치를 새롭게 가리키는 방식이다.
- B트리에 모든 키가 들어가는게 아닌 범위 사이 경계 역할을 하는 키만 축약에 쓴다.
- 데이터가 들어있는 리프 페이지는 디스크 상에 연속되게 나타나게끔 시도한다.
- 트리 값에 포인터를 추가한다. 형제 포인터를 넣으면 상위 페이지로 돌아가서 탐색하지 않아도 바로 이동할 수 있다.
B 트리 vs. LSM 트리
- 쓰기 속도는 LSM 이 더 빠르다.
- 읽기 속도는 B 트리가 더 빠르다. LSM은 각 컴팩션 단계의 여러 데이터 구조와 SS 테이블을 확인해야하기 때문이다.
색인 안에 값 저장하는 법
- 값: 실제 값(로우, 문서, 정점) 이거나, 다른 로우를 가리키는 참조이거나
→ 참조일 땐 실제 로우를 힙 파일(heap file) 에 저장하고 순서 없이 저장한다.
힙 파일 접근 방식
- 키 변경하지 않고 실제 값만 갱신할 때 효율적이다. 색인을 수정할 필요가 없기 때문이다. 하지만 변경할 값이 이전 값보다 더 크다면 공간 확보를 위해 새 힙 위치를 가리키게 색인이 수정될 수도 있다.
클러스터드 색인(clustered index)
- 색인에 참조가 아닌 실제 값을 저장하는 방식
- 색인에서 힙 파일로 이동하는건 읽기 성능이 안 좋기 때문에 이 방식이 더 좋은 경우도 있다.
- Mysql InnoDB: 기본키는 클러스터드 색인, 보조색인은 기본키를 참조한다.
커버링 색인(covering index = index with included column)
- 클러스터드 색인(색인에 모든 로우 저장)과 비 클러스터드 색인(색인에 참조만 저장) 의 절충안
- 색인 안에 테이블의 컬럼 일부만 저장하여 일부 질의 응답에 가능하도록 한다. (="색인이 질의를 커버했다")
다중 컬럼 색인
- 여러 컬럼에 동시에 질의하는 경우 유용
결합 색인 (concatenated index)
- (성,이름) 처럼 하나의 키에 여러 필드를 순서대로 명시한다.
- 성을 가진 모든 이름은 찾을 수 있으나, 특정 이름을 가진 모든 사람은 찾을 수 없다.
- (elsboo) 몽고디비 색인 방식도 이렇다. 다중 컬럼 정해진 순서대로 탐색할 수 있다.
다차원 색인
- (위도, 경도) 처럼 동시에 검색할 때 쓴다.
- R 트리
full-text (전문) 검색과 fuzzy 색인
- 루씬은 용어 사전을 SS 테이블 같은 구조의 인메모리 색인을 사용한다. 인메모리 색인은 여러키 내 문자에 대한 유한 상태 오토마톤으로 트라이와 유사하다. 오토마톤은 레벤슈타인 오토마톤으로 변환할 수 있으며 특정 편집 거리 내 단어 검색을 제공한다. (????유한상태? 오토마톤?)
인메모리 DB
- 지속성을 목표로 한다.
- 어떻게? 디스크에 변경 로그 기록, 디스크에 주기적으로 스냅샷 기록, 다른 장비에 인메모리 상태 복제, 배터리 전원 공급 RAM 같은 특수 하드웨어 사용
- redis, couchbase 는 비동기로 디스크에 기록하기 때문에 약한 지속성을 제공한다.
OLTP vs. OLAP
OLTP(OnLine Transaction Processing, 온라인 트랜잭션 처리)
: 사용자 입력 기반으로 적은 수의 레코드만 찾는다. 사용자 입력 기반이기 때문에 대화식이다.
OLAP(OnLine Analytic Processing, 온라인 분석 처리)
: BI(비즈니스 인텔리전스, 데이터 기반으로 경영진이 더 나은 의사 결정을 하게끔 하는거) 를 위해 집계, 통계 같은 데이터 분석 패턴이다. 데이터 분석 목적으로 구축한 DB를 데이터 웨어하우스라 한다. OLTP 는 사업 운영에 중요하기 때문에 높은 가용성과 낮은 지연 시간의 트랜잭션 처리를 기대한다. 근데 OLAP를 위한 쿼리는 비싸기 때문에 OLTP 에 영향을 주지 않는 데이터 웨어하우스가 나왔다.

컬럼 지향 저장소
데이터 분석은 대부분 select * 같은 모든 컬럼이 팔요하지 않다. 수많은 로우에 접근하지만 통계의 필요한 몇 개의 컬럼만 필요할 뿐이다. 그래서 나온게 parquet 같은 컬럼 지향 저장소이다. 각 칼럼 별로 개별 파일에 저장하면 질의에 사용되는 컬럼만 읽고 분석하면 된다.

컬럼 압축
반복되는 데이터가 많다면 0이 9번, 1이 1번 -> 9,1 처럼 압축할 수도 있다.

레퍼런스
데이터 중심 애플리케이션 설계 3장

'SearchDeveloper > 데이터 중심 애플리케이션 설계' 카테고리의 다른 글
| [6] 파티셔닝 하는 방법, 리밸런싱 전략, 요청 라우팅 전략 (0) | 2023.07.01 |
|---|---|
| [5] 복제를 구성하는 방법과 동기화를 위한 노력 (0) | 2023.06.25 |
| [4] 데이터를 다른 시스템에 전송하기 위한 부호화 (인코딩) 와 호환성 (0) | 2023.06.15 |
| [2] 어떤 데이터 모델을 어떤 경우에 쓰면 좋을까? (0) | 2023.05.15 |
| [1] 데이터를 중심으로 하는 애플리케이션은 어떤 걸 생각해봐야할까? (2) | 2023.05.06 |



