
ElasticSearch refresh, flush API 동작 원리 (1): Lucene 관점
https://elsboo.tistory.com/18 ElasticSearch Lucene 인덱스 구조 엘라스틱 서치는 현업에서 많이 쓰이고 있는 오픈소스 검색엔진이다. 역색인 구조로 문서를 색인하며, 근실시간으로 문서를 검색할 수 있다.
elsboo.tistory.com
이전 글에서는 엘라스틱서치의 refresh, flush 동작 방식을 루씬 관점에서 살펴보았다. 이번 글에서는 동작 방식을 육안으로 확인해보고 엘라스틱서치가 제공하는 기능인 trasnslog 에 대해서도 알아볼 것이다.
<엘라스틱서치 관점에서>
루씬에서 세그먼트를 생성하는 2가지 작업을 엘라스틱서치에서는 다른 용어로 불린다.
| ElasticSearch API | Lucene |
| /refresh | flush 작업 수행 |
| /flush | commit 작업 수행 |
엘라스틱서치랑 루씬 둘 다 flush 용어가 있지만 서로 다른 작업이라는 것을 인지해야한다!
이제 엘라스틱서치 관점이니 flush 대신 refresh를, commit 대신 flush 라는 용어를 사용하겠다.
그럼 이제 문서를 색인한 후에 refresh, flush 를 수행했을 때 무엇이 변하는지 살펴보자
1) 문서 색인
먼저 인덱스를 생성하고,
PUT elsboo_index
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": { "properties": { "categorry": {"type": "text"} } }
}
해당 uuid 디렉토리의 0번 샤드로 이동하면 다음과 같은 초기 상태를 볼 수 있다.
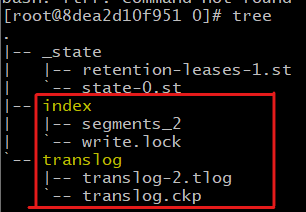
문서를 하나 색인한 직후의 모습은 이렇다.
PUT elsboo_index/_doc/1
{
"category": "food"
}

색인 직후 루씬과 엘라스틱서치는 다음과 같은 일을 한다.
- 루씬: 메모리 캐시에 데이터를 쓴다.
- 엘라스틱서치: translog 에 기록한다.
엘라스틱서치는 왜 translog 에도 데이터를 기록할까? 그건 바로 데이터의 안정성 때문이다. 루씬은 메모리 캐시에만 기록한 상태이기 때문에 서버가 다운되거나 장애가 나면 데이터가 그대로 유실될 것이다. 그래서 만약 유실됐다면 기록해뒀던 translog 를 보고 데이터를 복구 할 수 있는 것이다. 이것이 바로 엘라스틱서치가 고가용성을 내세우는 이유 중에 하나이다.
지금은 아직도 세그먼트가 만들어지지 않았으므로 문서 검색은 할 수 없는 상태이다.
2) /refresh
POST elsboo_index/_refresh 를 호출하거나 GET elsboo_index/_search 를 호출하면 이런 모습이 된다.

드디어 0번 세그먼트가 만들어졌고 검색이 가능한 상태가 된다. 하지만 아직 물리적으로 디스크에 쓰여진 상태는 아니기 때문에(= 루씬 commit 전이기 때문에) translog 에는 여전히 데이터가 남아있다.
3) /flush
드디어 /flush 를 하면
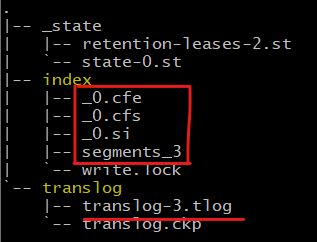

루씬 commit 을 하면서 segments_2 에서 segments_3 으로 증가되고 물리적인 디스크에 기록되었다. 그래서 이제부터는 translog 에 데이터가 남아있을 필요가 없기 때문에 translog-2 에서 translog-3 으로 바뀌며 데이터는 지워졌다.
참고
엘라스틱서치 실무 가이드 (책)
https://programming.vip/docs/in-depth-elasticsearch-index-creation.html
ElasticSearch refresh, flush API 동작 원리 (2): ElasticSearch 관점
글 읽어주셔서 언제나 감사합니다. 좋은 피드백, 개선 피드백 너무나도 환영합니다.
'SearchDeveloper > ElasticSearch' 카테고리의 다른 글
| [트러블슈팅] Too many dynamic script compilations within, max: [75/5m] (0) | 2022.11.16 |
|---|---|
| ElasticSearch Full GC 해결 과정 (2) | 2022.09.11 |
| ElasticSearch refresh, flush API 동작 원리 (1): Lucene 관점 (0) | 2022.07.22 |
| ElasticSearch Lucene 인덱스 구조 (0) | 2022.07.10 |
| Spring-Data-Elasticsearch VS. Rest-high-level-client (0) | 2020.10.25 |



