엘라스틱 서치는 현업에서 많이 쓰이고 있는 오픈소스 검색엔진이다. 역색인 구조로 문서를 색인하며, 근실시간으로 문서를 검색할 수 있다. 하지만 색인, 검색 기능을 엘라스틱 서치에서 직접 구현하지는 않는다. 해당 기능은 루씬이라는 오픈소스 자바 라이브러리를 임포트하여 사용한다. 즉, 엘라스틱 서치는 루씬이라는 검색 라이브러리를 코어로 하여 이것에 REST API, 관리 기능 등 여러가지 편의 기능을 붙인 검색엔진이다.
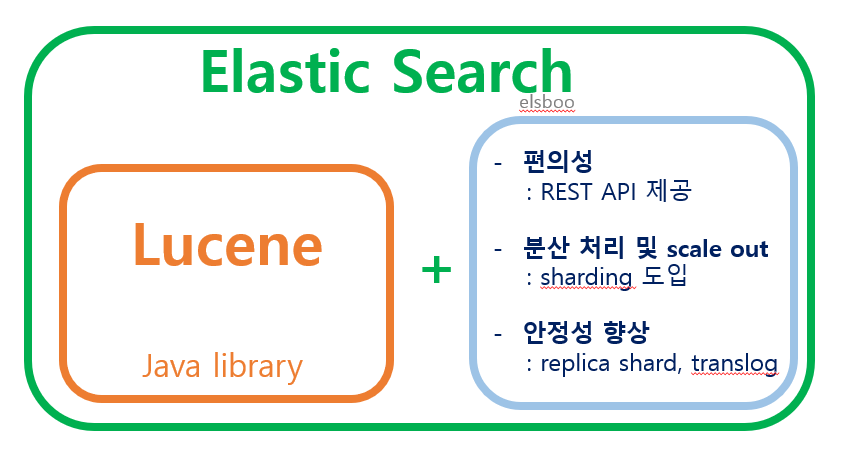
그래서 엘라스틱 서치의 인덱스 구조를 내핵까지 파헤친다면 그 끝은 결국 루씬이 만들어주는 역색인 구조의 파일이다. 그럼 엘라스틱 인덱스를 양파 까듯 까보자!

엘라스틱 서치 인덱스 ⊃ 샤드 ⊃ 루씬 인덱스 ⊃ 세그먼트 ⊃ 도큐먼트
<엘라스틱 서치 인덱스의 세계로>
먼저 인덱스를 하나 생성한다.
PUT elsboo_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
},
"mappings": { "properties": { "categorry": {"type": "text"} } }
}
키바나를 통해 확인해보면, 인덱스는 primary shard 3개로 구성된 것을 알 수 있다.
논리적으로 샤드로 구성되어있는 건 알겠는데, 실제 샤드는 물리적으로 어디에 저장되는 걸까? 다음 경로로 이동해보자.
${path.data}/nodes/0/indices${path.data} 는 config/elasticsearch.yml 에서 설정한 경로이다.

오! 인덱스의 uuid 와 같은 디렉토리가 하나 있다. 그 안으로 들어가보니,

숫자로 된 3개의 디렉토리가 있다. 그렇다. 엘라스틱서치 인덱스의 물리적인 저장 구조는 다음과 같다.
- ${path.data}/nodes/0/indices 에 위치한다.
- 하나의 인덱스는 본인 uuid와 똑같은 디렉토리를 갖는다.
- 그 안에는 primary shard 숫자 디렉토리를 갖는다.
<샤드의 세계로>
샤드는 분산 저장을 위해 루씬이 아닌 엘라서틱 서치가 도입한 개념이다. 인덱스 안의 많은 양의 도큐먼트를 여러 곳에 분산시키면서 서버의 수평적 확장(=scale out) 이 가능하다.

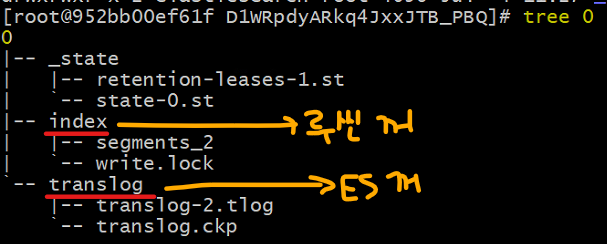
샤드 안에는 2개의 관리자가 존재한다.
- ./index: 루씬이 관리
- 색인된 문서가 반영구적으로 저장되는 공간이다.
- 세그먼트가 저장되는 공간이기도 하다.
- ./translog: 엘라스틱 서치가 관리
- 장애 발생 시 데이터 유실을 방지하기 위해 엘라스틱 서치가 도입한 방식이다.
- 문서 색인 직후 세그먼트가 바로 생성되는 것이 아니라 translog와 메모리버퍼에 먼저 기록된다.
- 루씬이 디스크에 물리적으로 기록하기 전에(=루씬 commit) 장애가 발생했을 때 translog 기록을 보며 데이터를 복구할 수 있다.
- flush API 호출 시 translog 내용은 삭제된다. 루씬 commit이 수행되고 데이터가 물리적으로 디스크에 쓰여지기 때문이다.
세그먼트와 translog 에 대한 자세한 내용은 도큐먼트가 색인되는 상황을 재현하여 다음 글로 작성해보겠다.
<세그먼트의 세계로>
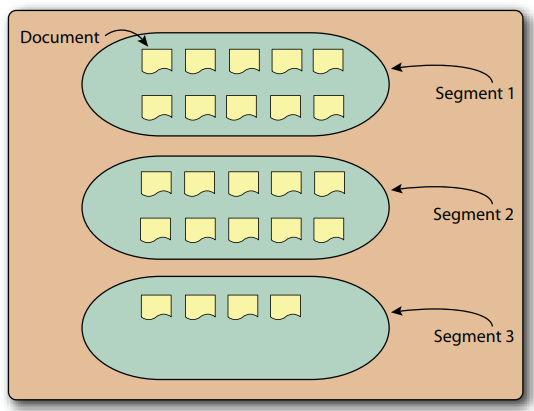
- 세그먼트는 루씬이 관리하는 개별적인 색인이다. 결국 엘라스틱 서치 인덱스의 데이터는 세그먼트라는 각각의 조각조각으로 구성되어 있는 것이다.
- 검색할 때 세그먼트 하나하나를 조회한 후 그 결과를 병합에 리턴한다.
- 루씬은 하나의 세그먼트를 단일 파일로도 구성할 수 있고, 여러 파일로도 구성할 수 있다. 엘라스틱 서치는 아래 그림과 같이 한 세그먼트를 다중 색인 파일로 구성한다.

| file | description |
| _0.si | 0번 세그먼트의 메타데이터 |
| _0.cfs | 0번 세그먼트에서 자주 쓰이는 엔트리 |
| _0.cfe | 0번 세그먼트의 모든 엔트리 테이블 (.cfs의 엔트리 포함) |
| segments_N | 모든 세그먼트 참조를 보관하는 메타파일. 색인을 열 때 가장 먼저 읽는다. N은 커밋 횟수이다. |
※ 색인 파일에 대해 더 자세한 설명을 원한다면:
https://lucene.apache.org/core/8_9_0/core/org/apache/lucene/codecs/lucene87/package-summary.html
세그먼트 구성에는 위 말고도 다양한 확장자 파일이 존재하며 각 파일들은 아래 그림처럼 서로 유기적으로 연결되어 있다.

<도큐먼트의 세계로>
도큐먼트는 사용자가 입력한 데이터이다. 검색 속도를 빠르게 하기 위해 텀이 키가 되는 역색인 구조로 세그먼트 안에 있다.
색인된 도큐먼트 내용은 세그먼트 안에 바이너리 파일로 저장되어 있기 때문에 육안으로 확인할 수는 없다.

하지만 바이너리 안에 드문드문 도큐먼트의 흔적이 보이긴 한다! (도큐먼트 중 computer 와 food 가 있다.)
참고
루씬 인 액션 (책)
엘라스틱서치 실무 가이드 (책)
https://programming.vip/docs/in-depth-elasticsearch-index-creation.html
ElasticSearch Lucene 인덱스 구조
글 읽어주셔서 언제나 감사합니다. 좋은 피드백, 개선 피드백 너무나도 환영합니다.
'SearchDeveloper > ElasticSearch' 카테고리의 다른 글
| [트러블슈팅] Too many dynamic script compilations within, max: [75/5m] (0) | 2022.11.16 |
|---|---|
| ElasticSearch Full GC 해결 과정 (2) | 2022.09.11 |
| ElasticSearch refresh, flush API 동작 원리 (2): ElasticSearch 관점 + translog (0) | 2022.07.30 |
| ElasticSearch refresh, flush API 동작 원리 (1): Lucene 관점 (0) | 2022.07.22 |
| Spring-Data-Elasticsearch VS. Rest-high-level-client (0) | 2020.10.25 |


