레디스에서 데이터 영구 저장하기
- 레디스는 메모리에서 관리되기 때문에 인스턴스가 재시작되면 모두 날라갈 가능성이 있으니 백업 정책은 중요하다.
- 복제 정책도 있으나 서로 목적이 다르고(복제는 가용성, 백업은 데이터 복구), 의도치 않게 데이터 삭제 커맨드가 실행되면 복제 정책으로도 복구할 수 없다.
백업하는 방법 2가지: RDB, AOF
- AOF(Append Only File): 메모리 변경있는 모든 쓰기 작업을 차례대로 기록, 복원할 때 커맨드 실행해가며 데이터 재구성
- RDB(Redis Data Base): 스냅샷 방식. 일정 시점에 메모리에 저장된 데이터 전체 저장

- 실제로 RDB는 바이너리 형태로, AOF는 RESP(레디스 프로토콜)형태로 저장된다.

- 장단점
- RDB: AOF보다 복원이 빠르나 특정 시점으로 복구는 불가능
- AOF: 원하는 시점으로 복구 가능하나 파일 크기 크고 주기적으로 압축해 재작성해야 한다.
- AOF, RDB 동시에 설정하는 것 권장함
- 데이터 복원할 때 AOF 존재하면 AOF로 먼저 복구한다. (레디스가 AOF가 더 내구성이 보장된다고 판단해서)
- 복원 가능 시점
- 서버 재시작할 때. 레디스 인스턴스 실행 도중에 파일 읽어올 순 없다.
RDB 방식의 데이터 백업
- 가장 단순한 방법
- 원하는 시점에 메모리 스냅샷 찍듯 저장할 수 있어서 백업에 적합한 파일 형태
- 원격 저장소에 백업 파일 옮겨 놓으면 데이터 센터 장애도 대처할 수 있다.
- 하지만 손실 가능성 최소화하는 서비스에는 RDB가 적절하지 않다. 백업 이후 부터 장애 발생 시간까지의 변경분은 손실될 수 있어서.
- RDB 생성하는 법 3가지: 설정 파일에서 자동으로, 커맨드로, 복제 시 자동으로
1) 설정 파일에서 특정 조건에 자동으로 RDB 파일 생성하도록 설정
save, dbfilename, dir, CONFIG
# $1초 내 $2개 이상의 키가 변경된 경우 RDB 생성
save 3600 1
save 300 100
save 60 10000
127.0.0.1:6379> CONFIG GET save
1) "save"
2) "3600 1 300 100 60 10000"
127.0.0.1:6379> CONFIG GET dbfilename
1) "dbfilename"
2) "dump.rdb"
127.0.0.1:6379> CONFIG GET dir
1) "dir"
2) "/data"
# RDB 백업 설정 비활성화
127.0.0.1:6379> CONFIG SET save ""
OK
127.0.0.1:6379> CONFIG GET save
1) "save"
2) ""
127.0.0.1:6379> CONFIG REWRITE
(error) ERR The server is running without a config file
save 900 1900초 내 키 1개 이상 변경되면 RDB생성함- save계속하면 오버라이드가 아니라 백업 설정이 add됨
CONFIG GET dbfilenamedir경로에 dbfilename으로 RDB파일 저장된다.CONFIG SET save ""RDB 백업 비활성화CONFIG REWRITEredis.conf 파일 재작성- 실행중인 레디스에 바로 반영되지 않음. 만약 rewrite 안 하면 설정 영구 저장 안돼서 나중에 재기동할 때 반영안돼있을 것
2) RDB 파일 생성 커맨드 (수동으로)
SAVE, BGSAVE, LASTSAVE
127.0.0.1:6379> SAVE
OK
127.0.0.1:6379> BGSAVE
Background saving started
127.0.0.1:6379> BGSAVE SCHEDULE
Background saving started
127.0.0.1:6379> LASTSAVE
(integer) 1770380360
SAVE동기로 파일 생성. 모든 클라 요청 차단되므로 비추천.BGSAVEfork호출해 자식 프로세스 생성하여 백그라운드로 파일 생성- 이미 백그라운드 저장되고 있을 때 또
BGSAVE실행하면 에러 반환함BGSAVE SCHEDULE실행하면 실행중인 저장 작업 끝나고 수행함.
- 이미 백그라운드 저장되고 있을 때 또
3) 복제 사용하면 자동으로 RDB파일 생성됨
- 복제본에서
REPLICAOF커맨드로 복제 요청하면 마스터노드에서 RDB 파일 새로 생성해 복제본에 전달한다. - 혹은 이미 복제 연결된 상태에서 네트워크 등 이슈로 복제 재연결되면 이 때도 마스터노드가 RDB 파일 전송한다.
AOF 방식의 데이터 백업
- 쓰기 작업 로그 차례로 기록하기 때문에
FLUSHALL로 데이터 모두 날려버려도 복구 가능- AOF 파일 열어서
FLUSHALL커맨드 직접 삭제하고 레디스 재시작
- AOF 파일 열어서
- 설정파일에서
appendonly yes로 하면 AOF 파일에 주기적으로 저장된다.appendfilename,appenddirname으로 파일, 디렉토리명 저장- 버전 7.0이상 부터 AOF 파일은 여러 개로 저장됨.
appenddirname하위에.
AOF파일에 어떻게 저장되는가
- 메모리에 변경이 일어난 쓰기 커맨드만 AOF파일에 저장한다.
127.0.0.1:6379> SET k1 apple # 저장
OK
127.0.0.1:6379> DEL non_EX # 저장 안 함
(integer) 0
AOF에 RESP(레디스 프로토콜)형식으로 저장된다.
- BRPOP(블로킹)은 RPOP으로 치환되어 기록된다.
- INCRBYFLOAT counter 50 은 SET counter 50으로 치환된다. 레디스가 실행되는 아키텍처에 따라 부동소수점 처리 방식 다를 수 있어서.
# GET name 이 RESP로 어떻게 저장되는가
*2 <-- 인자가 2개인 배열이다
$3 <-- 첫 번째 인자는 3글자다
GET
$4 <-- 두 번째 인자는 4글자다
name- 인스턴스가 실행되는 시간에 비례해서 AOF파일 크기가 계속 증가함 → 파일 재구성 필요!
AOF파일 재구성하는 방법
- 점점 커지는 AOF파일을 주기적으로 압축시키는 재구성(rewrite) 필요
- 특정 조건 만족하면 재구성되거나 커맨드로 실행 가능
- 재구성은 레디스 메모리에 있는 데이터를 읽어서 새로운 파일로 저장하는 형태
aof-use-rdb-preamble yes이면 RDB파일로도 저장
- AOF도 파일 재구성할 때 fork()로 자식 프로세스 생성해 백그라운드에서 진행한다.
레디스 7.0이전: RDB, AOF가 한 파일에
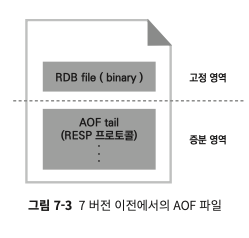
- 파일의 위는 RDB 고정 데이터, 아래는 AOF 증분 영역
AOF파일 만드는 과정

1) fork로 백그라운드에서 임시파일에 현재 데이터 저장
2) 백그라운드 돌고 있는 동안의 변경분은 인메모리 버퍼와 AOF파일에 동시 기록
3) 백그라운드 끝나면 인메모리 버퍼의 데이터를 임시 파일 마지막에 추가 (ES 전체 색인 중 동적 따라잡기!)
4) 임시 파일로 기존 AOF 덮어쓰기
레디스 7.0 이후: RDB, AOF파일 분리
구조

- menifest 파일이 도입되어 base, increase영역이 각각 어떤 파일에 쓰고 있는지 관리
- 세 파일은
appenddirname폴더 내 저장 - AOF재구성 될 때마다 seq 증가
- menifest 파일의 seq값이랑 파일명 seq도 변경됨
재구성 과정
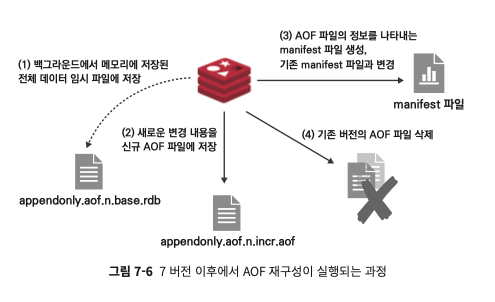

1) fork()로 생성한 자식 프로세스가 레디스 메모리 데이터 읽어와 base 임시 파일에 저장
2) 백그라운드 저장 진행되는 동안 변경분은 AOF파일에 저장
3) 백그라운드 끝나면 임시 manifest 파일 생성 후 변경된 버전으로 업데이트
4) 생성된 임시 manifest 파일로 기존 manifest 파일 덮어씌우기, 이전 버전 RDB, AOF파일 삭제
파일이 분리되어있어 훨씬 간단함
aof-use-rdb-preamble no면 base.rdb가 아니라 base.aof의 RESP로 저장됨- AOF 재구성 과정은 모두
순차 입출력(sequential I/O)이라 디스크 접근하는 모든 과정이 굉장히 효츌적)- AOF는 로드하는 용도로만 사용해서 검색할 필요가 없기 때문에
랜덤 입출력(random I/O)을 고려할 필요가 없다. 
- AOF는 로드하는 용도로만 사용해서 검색할 필요가 없기 때문에

1) 설정 파일에서 특정 조건에 자동으로 AOF 파일 재구성하도록 설정
auto-aof-rewrite-percentage 100마지막으로 재구성됐던 AOF 파일 크기보다 100%커지면 재구성 시도
- AOF 파일 크기는
INFO Persistence로 확인 가능- ```java
127.0.0.1:6379> INFO Persistence
Persistence
aof_current_size:186830
aof_base_size:1455802
aof\_current\_size가 aof\_base\_size 값 x2여야 재구성 시작
```java
auto-aof-rewrite-min-size 64mb
최소 64mb 이상이어야 재구성 시작
- AOF 현재 사이즈가 0이거나 1KB 같이 작은 값이면 너무 빈번히 재구성 일어나기 때문
2) AOF 파일 생성 커맨드 (수동으로)
BGREWRITEAOF
127.0.0.1:6379> BGREWRITEAOF
Background append only file rewriting started
aof-timestamp-enabled no버전 7 이상부터 AOF 저장할 때 타임스탬프 남길 수 있다.
- 특정 타임스탬프 이후로 지우기 가능 (
redis-check-aof프로그램 사용)src/redis-check-aof --truncate-to-timestamp 1669832844 appendonlydir/appendonly.aof.manifest- AOF파일 변경되는거라 백업 권장
- 타임스탬프 옵션 켜서 만든 AOF파일은 7 버전 미만의 레디스와 호환되지 않는다.
# AOF 상태 확인
src/redis-check-aof appendonlydir/appendonly.aof.manifest
# AOF파일 복구
src/redis-check-aof --fix appendonlydir/appendonly.aof.manifest
AOF 손상 시 저 프로그램 --fix로 실행해서 복구 가능
AOF 파일의 안전성
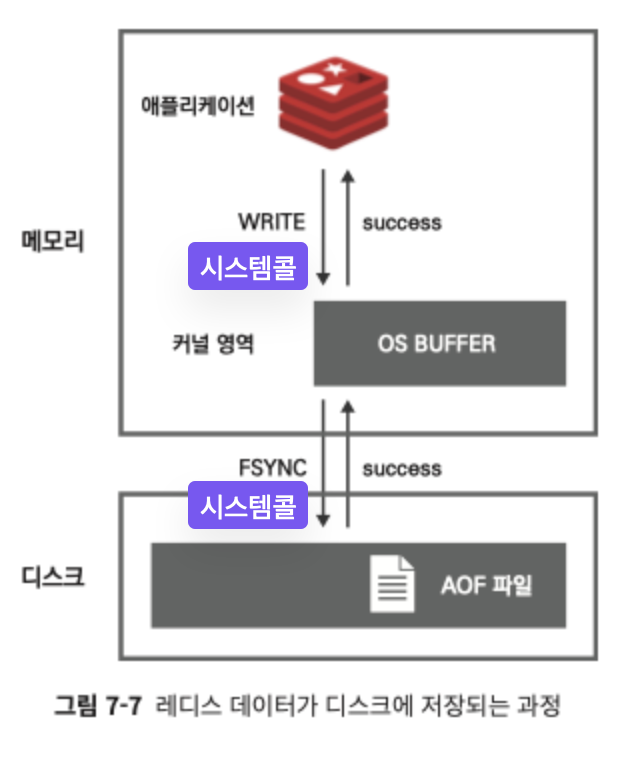
- OS단에서 애플리케이션이 파일에 데이터 저장하고자 할 때 곧바로 디스크에 저장되지 않는다.
- 앺이 wrtie() 시스템 콜 호출하면 커널 영역의 OS 버퍼에 임시로 담는다.
- OS가 커널 여유있다 판단하거나 30초 지나면 커널 버퍼의 데이터를 실제로 디스크에 내려 쓴다.
- fsync() 시스템 콜 호출하면 OS 부하 있더라도 무조건 디스크에 플러시된다.
- 레디스
APPENDFSYNC옵션으로 fsync() 호출 제어 가능APPENDFSYNC no: AOF 파일에 저장할 때 write() 시스템 콜만 호출. 쓰기 성능 가장 빠름APPENDFSYNC always:AOF 파일에 저장할 때 항상 write(), fsync() 시스템 콜 호출. 쓰기 성능 가장 느림APPENDFSYNC everysec: 디폴트값. AOF 파일에 저장할 때 write() 시스템 콜만 호출, 1초에 한 번 fsync() 호출. 쓰기 성능 no 일때랑 거의 비슷. 권장함
백업 사용할 때 주의할 점
인스턴스 maxmemory 값은 실제 서버 메모리보다 작게 설정하라
BGSAVE로 RDB파일 저장하거나 AOF 재구성할 때 fork()로 자식 프로세스 생성함- 자식 프로세스는 레디스 메모리를 그대로 파일에 저장하고 부모 프로세스는 다른 메모리의 데이터 이용해 클라 요청 처리해야함
- 이때 copy-on-write 방식으로 메모리 데이터를 하나 더 복사해 백업 진행하면서 클라 요청 처리하면서 데이터 조회/수정 진행한다.
- 그럼 모든 데이터 변경되면 기존 메모리 사용량의 최대 2배가 되므로 maxmemory 너무 서버 스펙과 가까이 잡으면 OOM 발생 가능 (복사본 메모리는 maxmemory 범위로 안 치나봄)
- RAM 4GB → maxmemory는 램의 50%
- RAM 8GB → maxmemory는 램의 58%
- RAM 16GB → maxmemory는 램의 63%
- RAM 32GB → maxmemory는 램의 65%
- RAM 64GB → maxmemory는 램의 66%
(참고) Copy On Write(COW)
→ fork로 자식 생성되면 처음엔 부모랑 같은 메모리 주소 바라봤다가 데이터 변경되면 그 때 메모리 페이지 복사해서 따로 보게 해서 메모리 효율적으로 사용할 수 있음.
https://code-lab1.tistory.com/58
리소스가 복제되었지만 수정되지 않은 경우에 새 리소스를 만들 필요 없이 복사본과 원본이 리소스를 공유하고, 복사본이 수정되었을 때만 새 리소스를 만드는 리소스 관리 기법을 말한다.
OS의 Copy On Write
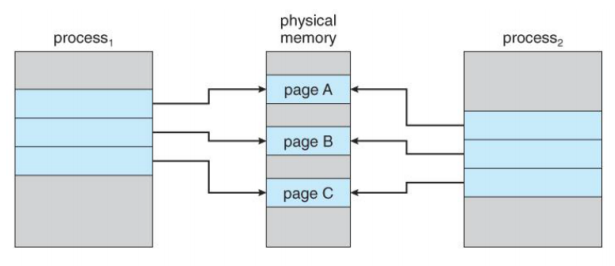
- OS에서의 COW는 fork() 기능과 관련이 깊다. fork()를 수행하면 자식 프로세스가 부모프로세스의 복사본이 된다. 그런데 이때 대부분 fork() 이후 exec()를 수행해 새로운 프로세스를 overwrite하게 된다. 즉, 복사를 하고 바로 exec()를 통해 새로운 프로세스를 만들게 된다. 이것은 overhead가 발생하게 되므로 비효율적이다.

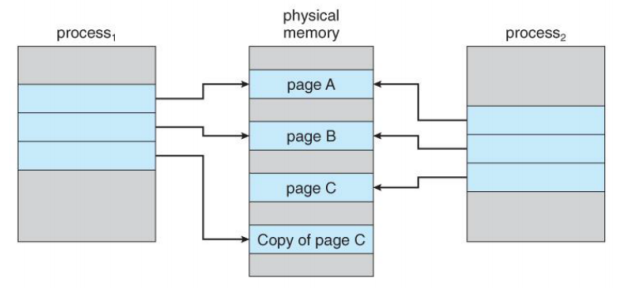
- 따라서 COW를 이용해 자식 프로세스가 같은 페이지를 공유하게 하면 된다. 만약 자식 프로세스에 수정이 일어난다면 그때 Copy를 수행하면 된다. 위와 같은 상황에서 만약 page C가 변경된다면, 아래와 같이 된다.

- page C의 복사본을 할당하고, 이를 가리키게 하면 된다.
- 이런식으로 내용이 바뀌지 않을 때까지는 페이지를 공유하고, 내용이 변경된다면 새로운 page를 할당해서 복사를 해주어 복사에 드는 비용(overhead)를 감소시킬 수 있다.
레퍼런스
개발자를 위한 레디스 책
글 읽어주셔서 언제나 감사합니다. 좋은 피드백, 개선 피드백 너무나도 환영합니다.
'SearchDeveloper > 개발자를 위한 레디스' 카테고리의 다른 글
| 6장 레디스를 메시지 브로커로 사용하기 (1) | 2026.02.08 |
|---|---|
| 5장 레디스를 캐시로 사용하기 (0) | 2026.02.07 |
| 4장 레디스 자료 구조 활용 사례 (0) | 2026.02.07 |
| 3장 레디스 기본 개념 (0) | 2026.01.16 |
| 2장 레디스 시작하기 (1) | 2026.01.16 |



