캐시
원본 데이터 저장소보다 더 빠르고 효율적으로 접근할 수 있는 임시 데이터 저장소
목표: 응답속도 줄이기
- 부가 효과: 원본 저장소 리소스 줄일 수 있고 원본 저장소가 장애난 상황에서 캐시에서 가져오기 때문에 장애 영향 줄일 수 있다.
캐시 적용하면 좋은 경우
- 원본 저장소에서 매번 계산을 해서 가져온다거나 읽기 시간이 오래걸리는 경우
- 캐시에서 가져오는 속도가 더 빠른 경우
- 캐시에 저장된 데이터가 잘 변하지 않는 경우
- 자주 검색되는 데이터일 경우
캐시로서 레디스 쓰면 좋은 점
- 키-값 또는 다양한 자료구조 지원으로 저장/반환할 때 변환 과정없어도 돼서 간단하다.
- 메모리 위에 존재해서 굉장히 빠르다.
- 센티널, 클러스터 사용하면 자동으로 장애 감지해 페일오버돼서 고가용성이다.
- 클러스터 사용하면 스케일아웃도 쉽다.
캐싱 전략: 레디스를 캐시로써 어떻게 배치할 것인가
[읽기 전략] look aside 구조


- 가장 일반적인 배치 방법
- 애플리케이션이 캐시 먼저 확인하여 데이터 있으면(캐시 히트) 읽고 없으면(캐시 미스) 원본 저장소에서 읽고 캐시에 저장한다.
- 장점: 레디스 문제생겨도 원본 저장소에서 가져오면 돼서 바로 장애로 이어지지 않음.(하지만 커넥션 몰리면 원본 저장소 부하로 인해 어케될 지 모름)
lazy loading구조 - 레디스에 데이터 없을 때만 레디스에 저장됨- → 레디스 처음 투입되거나 원본저장소 데이터 처음 생성된 상황이라면? 모두 캐시 미스나서 시스템 부하 일어날 것
- 해결:
cache warming. 미리 원본DB에서 캐시로 데이터 밀어넣는다.
쓰기 전략
- 원본 데이터가 변경될 때 캐시에 반영 안되면 원본과 캐시 값이 다른
캐시 불일치(cache inconsistency)현상 일어남 → 쓰기 전략 필요
[쓰기 전략1] write through
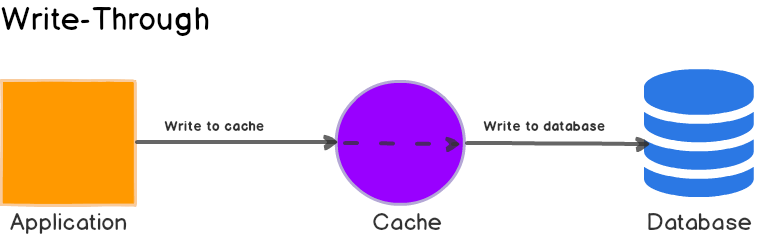
- 원본DB 업데이트할 때마다 캐시에도 업데이트 해주는 방식
- 데이터를 쓰는 시간이 많이 소요될 수 있다.
- 다시 접근하지 않을 데이터가 캐시에 저장될 수 있기 때문에 리소스 낭비 줄이기 위해 TTL 걸어두는 것 추천
[쓰기 전략2] cache invalidation
- 원본DB 업데이트할 때마다 캐시에서 데이터 삭제한다.
- 데이터 삭제가 삽입보다 리소스 훨씬 적게 사용해서
write through의 단점 보완
- 데이터 삭제가 삽입보다 리소스 훨씬 적게 사용해서
[쓰기 전략3] write behind (write back)

- 업데이트 요청 들어오면 캐시에만 업데이트하고 비동기적으로 원본DB에 업데이트하기
- 쓰기가 빈번하게 발생하는 상황에선 바로 원본DB에 업데이트하면 많은 디스크 I/O를 유발해 이 방법이 좋을수도.
- 실시간으로 정확하지 않아도 되는 경우(ex. 좋아요-빈번한 트래픽)에 추천
- 하지만 원본DB에 업데이트하기 전에 캐시 장애나면 데이터 유실될 수 있다.
만료시간
- 캐시는 원본DB보다 적은 데이터를 저장하는 서브셋
- 메모리에 저장하기 때문에 가득 차지 않게 삭제하는 것도 중요
- 메모리 공간 효율적으로 관리하기 위
EXPIRE, TTL, PEXPIRE, PTTL
127.0.0.1:6379> SET a 100
OK
127.0.0.1:6379> EXPIRE a 60
(integer) 1
127.0.0.1:6379> TTL a
(integer) 35 // 남은 초
127.0.0.1:6379> SET a 100 EX 60
OK
127.0.0.1:6379> TTL a
(integer) 58
// INCR는 TTL 안 사라짐
127.0.0.1:6379> INCR a
(integer) 101
127.0.0.1:6379> TTL a
(integer) 46
// RENAME은 TTL 안 사라짐
127.0.0.1:6379> RENAME a b
OK
127.0.0.1:6379> TTL a
(integer) -2
127.0.0.1:6379> TTL b
(integer) 35
// 키 만료됨
127.0.0.1:6379> TTL b
(integer) -2
// SET 덮어쓰기는 TTL 사라짐
127.0.0.1:6379> SET a 100 EX 60
OK
127.0.0.1:6379> TTL a
(integer) 58
127.0.0.1:6379> SET a 100
OK
127.0.0.1:6379> TTL a
(integer) -1EXPIRE a 60a 키가 60초 후 만료되게 설정SET a 100 EX 60EX(expire) 60초 만료 설정TTL a남은 초 확인INCR a,RENAME a b로는 TTL 변하지 않는다.SET a 100으로 덮어쓰기 하면 TTL 사라진다.
키가 만료됐다해도 바로 메모리에서 삭제되는 것은 아니다.
- passive 방식: 클라이언트가 키에 접근하고자 할 때 만료된 키라면 그 때 삭제됨. 접근 시도가 있어야 삭제되는 방식이라 접근이 없는 키는 삭제가 어려움
- active 방식: 알아서 확인하고 삭제함
- TTL 있는 값 중 20개 랜덤 반환
- 만료된 키 모두 삭제
- 만약 20개 중 25%이상의 키가 삭제됐다면 20개 다시 랜덤 추출해서 확인
- 아니면 기존 남은 키 중에서 다시 확인
- 1초에 10번씩 수행
둘 다 자동으로 작동함(블로그)
메모리 관리와 maxmemory-policy설정
maxmemory-policy: 메모리 용량 꽉 찼을 때 어떤 데이터를 삭제할건지 정하는 정책
echo "maxmemory-policy allkeys-lru" | sudo tee -a /etc/redis.conf
noevction
- 기본 값
- 데이터 가득차도 삭제 안 한다.
- 더 이상 저장할 수 없다는 에러 반환하기 때문에 장애로 이어질 수 있어 권장하지 않는다.
- 삭제로직을 애플리케이션에서 관리할 거라면 설정 가능
LRU evction (Least-Recently Used)
- 가장 최근에 사용이 안 된 데이터부터 삭제
volatile-lru: 만료 시간 설정돼있는 키만 LRU 방식으로 삭제함- 삭제되면 안되는 키는 만료 시간 설정 안 하면 됨
- 모든 키가 만료 시간 없으면 noevction이랑 같게 돼서 데이터 저장 할 수 없다는 에러 반환
allkeys-lru: 모든 키에 대해 LRU 삭제 적용- 잘 모르겠으면 이 옵션 권장
LFU evction (Least-Frequently Used)
- 가장 자주 사용되지 않는 데이터부터 삭제
volatile-lfu: 만료 시간 설정돼있는 키만 LFU 방식으로 삭제함allkeys-lfu: 모든 키에 대해 LFU 삭제 적용
LRU, LFU 모두 근사 알고리즘으로 구현됐다. 정확하게 찾아내는 건 불필요하게 리소스 사용하기 때문.
특정 키를 근사치로 찾아내 효율적으로 데이터를 삭제하는 방법으로 작동함을 알아두자.
maxmemory-samples
- lru 의 정밀도라고 볼 수 있다.
- 정밀할 수록 더 많은 비용이 들어가기 때문에, 적당한 값을 권장한다.
- 5가 기본. 10은 정밀. 3은 빠르지만 상대적 비정밀RANDOM evction
volatile-random,allkeys-random- 랜덤키삭
- 삭제될 키 계산 안해도 돼서 레디스 부하 줄일 수 있음
- 금방 사용될 키가 삭제되면 다시 레디스에 넣어줘야해서 비권장함.
volatile-ttl
- 만료 시간이 얼마 안남은 키 미리 삭제
- 근사 알고리즘 사용
캐시 스템피드 (cache stampede)

현상
- look aside 방식에서 여러 앺에서 접근하는 레디스 키가 만료되어 삭제됐을 때, 모두 원본DB로 가서 읽기 요청 → 중복 읽기
- 각 앺에서 읽은 데이터를 레디스에 씀 → 중복 쓰기
- 원본DB 부하 줘서 서비스 영향 생길 수 있음.
- 한번 캐시 스템피드 현상이 발생하면 더 많은 데이터가 이 현상 영향 받게 돼서(계단식 실패, cascading failure) 더 큰 문제로 이어질 수 있다.
해결
1) 만료시간 너무 짧지 않게 설정
2) 만료되기 전에 미리 계산해서 갱신
ttl - (random.random() * expiry_gap) > 0
import random
def fetch(key, expiry_gap):
ttl = redis.ttl(key) # 현재 남은 TTL 확인
if ttl - (random.random() * expiry_gap) > 0:
return redis.get(key) # 캐시된 값 반환
else:
value = db.fetch(key) # DB에서 데이터 조회
redis.set(key, value, KEY_TTL) # 캐시 갱신
return value
# 사용 예시
fetch("hello", 2)- TTL - 랜덤 값 > 0이면 캐시된 데이터를 그대로 사용, 음수면 DB에서 데이터를 가져와 캐시에 저장
- 적절한 expiry_gap 설정이 중요
PER(Probabilistic Early Recomputation)
currentTime - ( timeToCompute * beta * log(rand()) ) > expiry- currentTime : 현재 남아있는 캐시 만료 시간
- timeToCompute : 캐시된 값을 다시 계산하는 데 걸리는 시간
- beta (β) : 기본적으로 1.0보다 큰 값으로 설정 가능 (갱신 확률 조절)
- rand() : 0 ~ 1 사이의 랜덤 값을 반환하는 함수
- expiry : 키를 재설정할 때 새로 적용할 만료 시간
→ 만료시간에 가까워질수록 true 반환 확률 증가
3) 만약 다량의 키가 만료 시간이 같아서 스템피드 현상이 일어난다면 만료 시간을 약간의 랜덤으로 설정
val ttl = 300 + Random.nextInt(30) // 300초 ~ 330초 사이 랜덤 TTL 적용
redisTemplate.expire("cache-key", ttl, TimeUnit.SECONDS)
세션 스토어로서의 레디스
세션
- 서비스 사용하는 클라이언트의 상태 정보
- ex. 로그인 된 클라가 누구인지, 사이트 내에서 어떤 활동 하고 있는지 저장. 사이트를 떠나면 세션 스토어에서 유저 정보 삭제한다.
- 장바구니에 담은 물건, 최근 본 아이템을 세션에 저장하면 로그인 된 동안 정보 계속 유지됨. 사용자 행동 분석도 가능
- ex. 로그인 된 클라가 누구인지, 사이트 내에서 어떤 활동 하고 있는지 저장. 사이트를 떠나면 세션 스토어에서 유저 정보 삭제한다.
- 많은 서비스에서 레디스를 세션스토어로 사용한다.
- 로그인 돼있는 동안 세션 데이터 끊임없이 읽고 쓰므로 빠른 응답 속도 필수이기 때문
세션스토어가 따로 필요한 이유
세션 스토어가 따로 있지 않고 웹 서버에 세션을 저장한다면? (sticky session)

- 유저의 세션이 한 웹 서버에만 종속됨
- 유저 요청이 다른 웹서버에 전달되면 세션 정보 없어서 보여지는 데이터가 있다 없다 할거라 문제
- 특정 웹 서버에 트래픽 몰려도 세션 의존 때문에 유저들을 다른 웹서버로 보낼 수 가 없어 트래픽 분산이 안됨
그럼 모든 세션을 모든 웹서버에 저장한다면? (all-to-all)

- 불필요한 저장 공간 차지. 세션을 다른 웹 서버들로 복사하기 위한 불필요한 네트워크 트래픽.
DB를 세션스토어로 활용한다면?

- 각 유저는 세션 활성화 되어있는 동안 세션 스토어에 활발하에 액세스한다.
- 세션스토어에서 응답 속도 느려지면 클라 응답 속도 저하 됨
세션스토어를 레디스로 분리!

- 세션이 웹 서버에 종속 안되기 때문에 웹 서버 트래픽 분산 가능
- 한 개 저장소이기 때무네 데이터 일관성 고려할 필요 없음
- RDB보다 빠른 응답 속도
세션은 hash로 구현하기 좋음

캐시와 세션의 차이
캐시

세션 스토어

레디스 데이터 관련
(캐시) DB의 완벽한 서브셋으로 동작
- 캐시 데이터 유실되더라도 DB에서 찾을 수 있음
(세션 스토어) 유저 로그인 한 동안 유저 데이터를 DB 말고 세션 스토어만 저장한다.
- 로그아웃할 때 세션은 종료되며, 이때 데이터 종류에 따라 DB에 영구적으로 보관할지, 삭제할지 결정된다.
- ex. 장바구니 담아논 상품은 영구 저장, 최근 본 상품은 삭제
- 세션 스토어 장애나면 데이터 손실될 수 있으니 신중한 운영 필요
데이터 공유 관련
(캐시) 캐시 데이터는 여러 앺에서 함께 사용할 수 있고, 함께 사용할수록 효율적임
(세션 스토어) 세션 스토어 데이터는 한 유저ID에 한해서만 유효함, 유저 간 공유하지 않음
레퍼런스
개발자를 위한 레디스 책
글 읽어주셔서 언제나 감사합니다. 좋은 피드백, 개선 피드백 너무나도 환영합니다.
'SearchDeveloper > 개발자를 위한 레디스' 카테고리의 다른 글
| 7장 레디스 데이터 백업 방법 (0) | 2026.02.08 |
|---|---|
| 6장 레디스를 메시지 브로커로 사용하기 (1) | 2026.02.08 |
| 4장 레디스 자료 구조 활용 사례 (0) | 2026.02.07 |
| 3장 레디스 기본 개념 (0) | 2026.01.16 |
| 2장 레디스 시작하기 (1) | 2026.01.16 |



