시스템을 세 가지 유형으로 나눌 수 있다.
- 서비스 (온라인) - 클라이언트로부터 요청이 들어오면 실시간으로 응답해야 함. 성능 지표: 응답 시간
- 일괄 처리 시스템 (오프라인) - 정해진 시간에 매우 큰 입력 데이터를 받아 처리하고 결과 데이터를 생성함. 성능 지표: 처리량 (10장)
- 스트림 처리 (준실시간) - 입력 이벤트가 발생한 직후 데이터를 받아 처리하고 생성함. (11장)
맵리듀스
- 2번 일괄 처리 알고리즘
- "구글을 대규모로 확장 가능하게 만든 알고리즘"
- 하둡, 카우치DB, 몽고DB 에서 구현됨
더 자세하게 알아보기 전에, 일괄 처리의 아이디어를 준 유닉스 시스템부터 살펴보자
유닉스 철학
유닉스의 데이터 처리 방식
로그 파일 분석 명령어

공백 분리 7번째 문자열을 정렬 → 중복 제거→ 내림 차순 정렬→ 위 5개만 순으로 정제하고 있다.
출력문

유닉스의 데이터 처리 아이디어
- 다른 방법으로 데이터 처리가 필요할 때 파이프를 연결하는 형식으로 연쇄 명령을 사용한다.
- 각 프로그램이 한 가지 일만 하도록 작성한다. 새 작업을 하려면 기존 기능을 고치는게 아니라 새로운 프로그램을 생성하라. => ex. sort
- 모든 프로그램의 출력은 다른 프로그램의 입력으로 쓰일 수 있다고 생각하라. => 동일 인터페이스
- 빠르게 써볼 수 있게 설계하고 구축하라
데이터 처리를 유연하게 함께 조합할 수 있는 이유
1.동일 인터페이스
- 모든 프로그램이 같은 입출력 인터페이스를 사용한다. (리눅스는 파일)
2.로직과 연결의 분리
- 각 프로그램은 연결되는 프로그램이 어떻게 구현됐는지 신경쓰지 않는다.
- ex. 어떻게 구현하든 상관없이 stdin 은 입력 받고, stdout 은 출력 하고, sort는 들어온 데이터를 정렬만 하면 된다.
3.투명성과 실험
- 명령 실행 시 입력 파일은 불변 처리되기 때문에 손상을 주지 않는다.
- 어느 시점이든 파이프라인 중단하고 출력물을 확인할 수 있다.
- 중간 결과물을 남겨놓으면 파이프라인의 중간 부터 재시작할 수 있다.
유닉스 도구의 단점
- 여러 입력이나 여러 출력을 받으려면 까다롭다.
- 프로그램 출력을 파이프를 이용해 네트워크와 연결하진 못한다.
- 단일 장비에서만 사용 가능하다
=> 하둡 같은 도구가 필요한 이유임!
맵리듀스
맵리듀스: HDFS 같은 분산 파일 시스템에서 대용량 데이터 처리하는 코드를 작성하는 프로그래밍 프레임워크
유닉스 도구와 비교했을 때
공통점
- 입력을 받아 출력을 만들어낸다.
- 입력을 수정하지 않기 때문에 출력은 생산하는것 외에 부수효과는 없다
다른점
- 유닉스는 입력,출력으로 stdin, stdout 를 사용하는데 하둡은 HDFS(분산파일시스템)의 파일을 입력, 출력으로 사용한다.
HDFS (Hadoop Distributed File System)
- 비공유 방식 사용 - 저장소 컴퓨터가 데이터센터 네트워크에 연결되어있으면 끝
- 각 노드에 데몬 프로세스가 돌고 있고 이 데몬으로 다른 노드의 파일을 접근할 수 있다.
- 네임노드(NameNode) 가 중앙 서버이며 특정 블록이 어떤 노드에 저장됐는지 추적한다.
- 개념적으로 하나의 큰 파일 시스템이고 데몬이 다른 노드에 저장된 디스크를 사용할 수 있게 해준다.
- 그래서 확장성이 뛰어나다.
- 노드가 죽는 걸 대비에 파일 블록은 여러 장비에 복제된다.
맵리듀스 작업 단계 4가지
1.입력 파일을 읽어 레코드(ex.개행) 단위로 쪼갠다.
2.각 레코드마다 매퍼 함수를 호출해 키와 값을 추출한다.
3.키를 기준으로 정렬한다.
4.정렬된 키-값 쌍을 대상으로 리듀스 함수를 호출해 출력 레코드를 생산한다.
맵리듀스 분산 실행
여기서 나오는 맵리듀스 장점: 우리가 병렬 실행 로직을 구현하지 않아도 여러 노드에서 병렬로 처리하도록 해준다.
하둡 맵리듀스의 매퍼, 리듀서 구현 실체: 자바의 특정 인터페이스 구현한 클래스
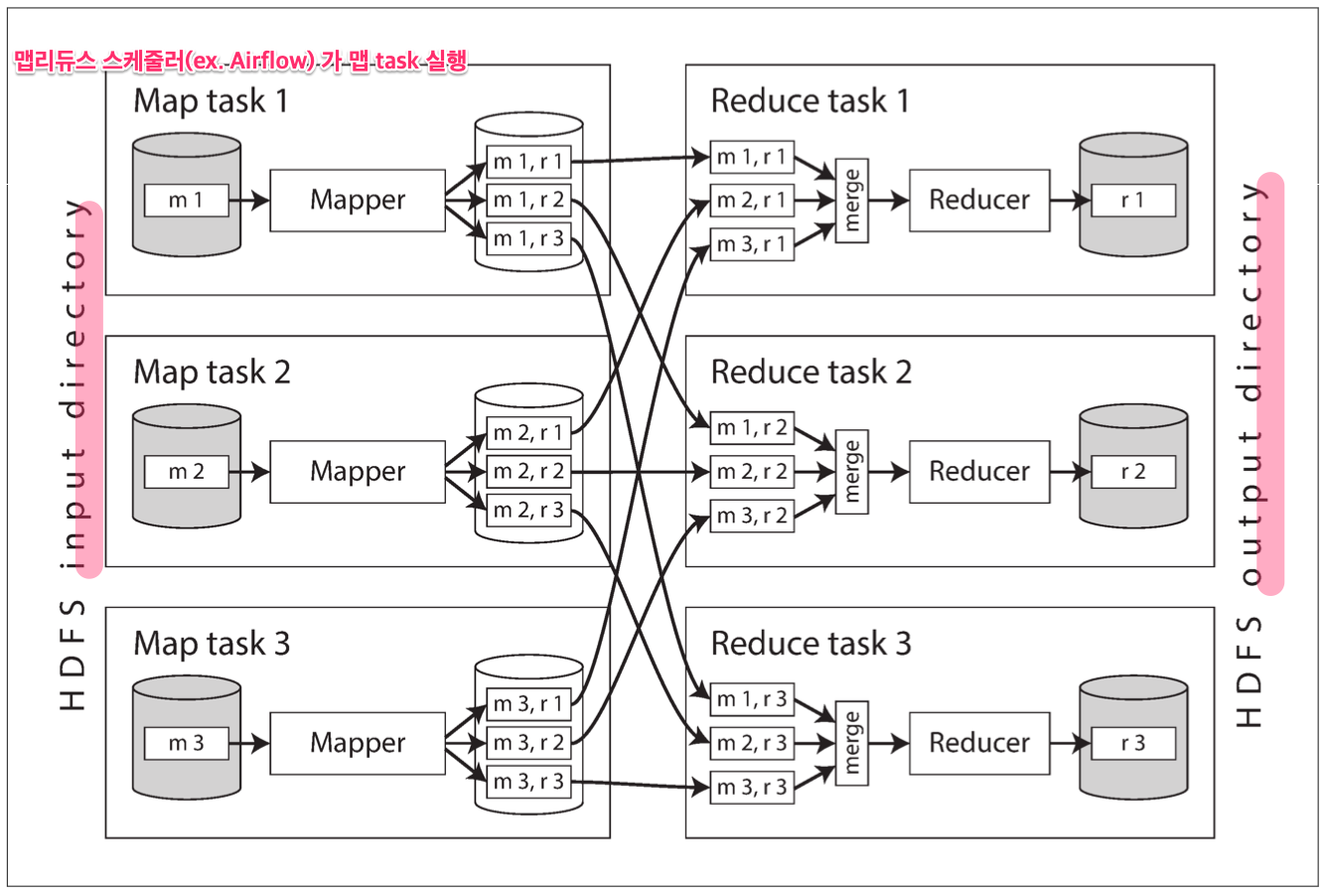
- 맵 태스크는 한 레코드 마다 호출돼 키-값 쌍의 데이터를 만들고, 같은 키 해시값을 가지는 데이터는 같은 리듀스 테스크에서 실행된다.
- 입력 데이터는 HDFS 파일이고 출력데이터도 HDFS 파일이다.
- 보통 맵리듀스 스케줄러는 네트워크 부하 감소 위해 입력 파일 있는 장비에서 실행된다.
- 매퍼 수는 입력 파일 매퍼 수에 따라 결정되고, 리듀서 수는 사용자가 결정한다.
매우 큰 데이터면 한 번의 정렬하기 쉽지 않을 텐데?
그래서 단계를 나누어 정렬을 수행한다.
1.맵 테스크는
- 키의 해시값 기반으로 출력을 리듀서 파티셔닝한다.
- 매퍼 로컬 디스크에 각 파티션을 정렬된 키-값 쌍 파일로 기록한다.
2.기록이 완료되면, 맵리듀스 스케줄러는 리듀서에게 알려준다.
3.리듀서는
- 각 매퍼에 연결해서 리듀서가 담당하는 파티션의 정렬된 키-값 쌍 파일을 다운로드한다.
※ shuffle: 리듀서가 매퍼의 정렬된 키-값 파일 복사하는거
맵리듀스 워크플로
: 원하는 값을 얻기 위해 출력을 다른 입력으로 연달아 맵리듀스 실행하는 작업
- 맵 리듀스 작업간 의존성 관리하는 스케줄러: Oozie, Azkaban, Luigi, Airflow, Pinball
리듀스 조인과 그룹화
- 맵리듀스는 색인 개념이 없다.
- 대량의 레코드로 집계 연산 하는 경우가 일반적이기 때문에 맵리듀스는 전체 파일을 읽는 full table scan 한다.
ex) 사용자 활동 이벤트 분석 - 연령 별 인기 URL 을 알아보자

정렬 병합 조인(sort-merge join)
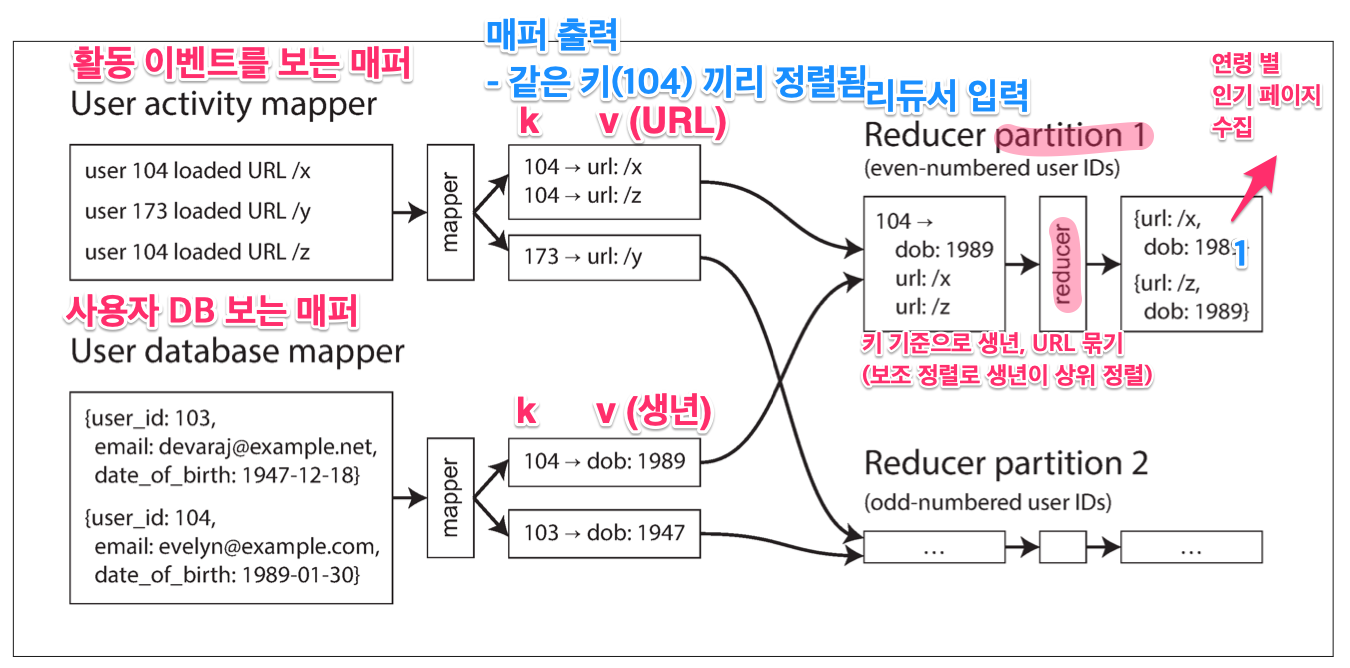
매퍼의 출력이 키로 정렬된 후에
리듀서가 두 조인을 병합한다.
한 키로 데이터가 쏠리는 거 해결하는 알고리즘
※ 이런 불균형한 레코드: 린치핀 객체(linchpin object) / 핫 키(hot key) 라고 부른다.
쏠린 조인 (skewed join)
- Pig 에서 사용
- 핫 키를 결정하기 위해 샘플링 작업 수행하고 핫 키라 판단되면 같은 키지만 다른 임의 리듀서들한테 보낸다.
- 핫 키와 조인할 다른 입력도 핫 키가 보내진 모든 리듀서에 복제한다.
- 복제 비용이 들지만 병렬화 효과가 더 크다
공유 조인(shared join)
- Crunch 에서 사용
- 핫 키를 명시적으로 지정하며, 이외에는 쏠린 조인과 비슷하다.
맵 사이드 조인 (map-side join)
- hive 에서 사용 - 핫 키를 테이블 메타데이터에 명시적으로 지정 후 맵 사이드 조인 실행
- 위에 껀 리듀스 사이드에서 조인한거고 입력 데이터 특정할 수 있으면 맵 사이드에서 조인 빠르게 가능
- 이외에도 브로드캐스트 해시 조인, 파티션 해시 조인, 맵 사이드 병합 조인 이 있다.
일괄 처리의 결과물
DB 질의의 경우
- OLTP(트랜잭션 처리) : 사용자에게 보여줄 소량의 데이터만 조회
- 분석: 대용량 데이터 그룹화, 집계해서 보고서 형태로 출력
일괄 처리의 경우
- 대용량 데이터 분석에 가깝지만 결과물은 보고서 형태가 아니라 다른 구조이다. (ex. 색인, 다른 DB, 파케이)
- 구글에서 색인 생성 위해 맵리듀스 사용됐었음
- 키-값 저장소가 맵리듀스 작업 내 DB 파일 구축하는 기능 지원(ex. 볼드모트, Hbase)
- 하둡에선 파케이 파일 형식 (스키마 기반 부호화)
레퍼런스
데이터 중심 애플리케이션 10장
'SearchDeveloper > 데이터 중심 애플리케이션 설계' 카테고리의 다른 글
| [12] 데이터 시스템의 미래 (끝) (0) | 2023.09.26 |
|---|---|
| [11] 스트림 처리 (1) | 2023.09.26 |
| [9] 일관성과 합의 (0) | 2023.08.10 |
| [8] 분산 시스템의 골칫거리 3가지 (0) | 2023.08.06 |
| [7] 트랜잭션 (0) | 2023.07.22 |


